 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Optimal Conditional Priors For Disentangled Representations
Oct 19, 2020



A large part of the literature on learning disentangled representations focuses on variational autoencoders (VAEs). Recent developments demonstrate that disentanglement cannot be obtained in a fully unsupervised setting without inductive biases on models and data. As such, Khemakhem et al., AISTATS 2020, suggest employing a factorized prior distribution over the latent variables that is conditionally dependent on auxiliary observed variables complementing input observations. While this is a remarkable advancement toward model identifiability, the learned conditional prior only focuses on sufficiency, giving no guarantees on a minimal representation. Motivated by information theoretic principles, we propose a novel VAE-based generative model with theoretical guarantees on disentanglement. Our proposed model learns a sufficient and compact - thus optimal - conditional prior, which serves as regularization for the latent space. Experimental results indicate superior performance with respect to state-of-the-art methods, according to several established metrics proposed in the literature on disentanglement.
LIBRE: Learning Interpretable Boolean Rule Ensembles
Nov 15, 2019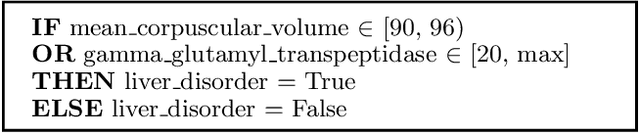
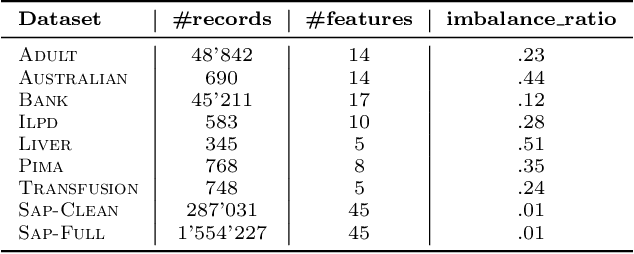
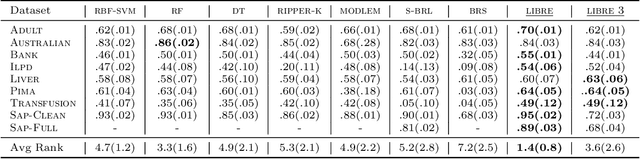
We present a novel method - LIBRE - to learn an interpretable classifier, which materializes as a set of Boolean rules. LIBRE uses an ensemble of bottom-up weak learners operating on a random subset of features, which allows for the learning of rules that generalize well on unseen data even in imbalanced settings. Weak learners are combined with a simple union so that the final ensemble is also interpretable. Experimental results indicate that LIBRE efficiently strikes the right balance between prediction accuracy, which is competitive with black box methods, and interpretability, which is often superior to alternative methods from the literature.