 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTackling extreme urban heat: a machine learning approach to assess the impacts of climate change and the efficacy of climate adaptation strategies in urban microclimates
Nov 08, 2024As urbanization and climate change progress, urban heat becomes a priority for climate adaptation efforts. High temperatures concentrated in urban heat can drive increased risk of heat-related death and illness as well as increased energy demand for cooling. However, estimating the effects of urban heat is an ongoing field of research typically burdened by an imprecise description of the built environment, significant computational cost, and a lack of high-resolution estimates of the impacts of climate change. Here, we present open-source, computationally efficient machine learning methods that can improve the accuracy of urban temperature estimates when compared to historical reanalysis data. These models are applied to residential buildings in Los Angeles, and we compare the energy benefits of heat mitigation strategies to the impacts of climate change. We find that cooling demand is likely to increase substantially through midcentury, but engineered high-albedo surfaces could lessen this increase by more than 50%. The corresponding increase in heating demand complicates this narrative, but total annual energy use from combined heating and cooling with electric heat pumps in the Los Angeles urban climate is shown to benefit from the engineered cooling strategies under both current and future climates.
Super Resolution for Renewable Energy Resource Data With Wind From Reanalysis Data (Sup3rWind) and Application to Ukraine
Jul 26, 2024With an increasing share of the electricity grid relying on wind to provide generating capacity and energy, there is an expanding global need for historically accurate high-resolution wind data. Conventional downscaling methods for generating these data have a high computational burden and require extensive tuning for historical accuracy. In this work, we present a novel deep learning-based spatiotemporal downscaling method, using generative adversarial networks (GANs), for generating historically accurate high-resolution wind resource data from the European Centre for Medium-Range Weather Forecasting Reanalysis version 5 data (ERA5). We achieve results comparable in historical accuracy and spatiotemporal variability to conventional downscaling by training a GAN model with ERA5 low-resolution input and high-resolution targets from the Wind Integration National Dataset, while reducing computational costs over dynamical downscaling by two orders of magnitude. Spatiotemporal cross-validation shows low error and high correlations with observations and excellent agreement with holdout data across distributions of physical metrics. We apply this approach to downscale 30-km hourly ERA5 data to 2-km 5-minute wind data for January 2000 through December 2023 at multiple hub heights over Eastern Europe. Uncertainty is estimated over the period with observational data by additionally downscaling the members of the European Centre for Medium-Range Weather Forecasting Ensemble of Data Assimilations. Comparisons against observational data from the Meteorological Assimilation Data Ingest System and multiple wind farms show comparable performance to the CONUS validation. This 24-year data record is the first member of the super resolution for renewable energy resource data with wind from reanalysis data dataset (Sup3rWind).
Supporting Energy Policy Research with Large Language Models
Mar 19, 2024
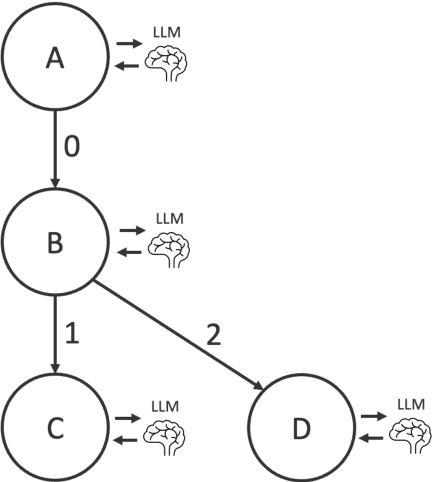


The recent growth in renewable energy development in the United States has been accompanied by a simultaneous surge in renewable energy siting ordinances. These zoning laws play a critical role in dictating the placement of wind and solar resources that are critical for achieving low-carbon energy futures. In this context, efficient access to and management of siting ordinance data becomes imperative. The National Renewable Energy Laboratory (NREL) recently introduced a public wind and solar siting database to fill this need. This paper presents a method for harnessing Large Language Models (LLMs) to automate the extraction of these siting ordinances from legal documents, enabling this database to maintain accurate up-to-date information in the rapidly changing energy policy landscape. A novel contribution of this research is the integration of a decision tree framework with LLMs. Our results show that this approach is 85 to 90% accurate with outputs that can be used directly in downstream quantitative modeling. We discuss opportunities to use this work to support similar large-scale policy research in the energy sector. By unlocking new efficiencies in the extraction and analysis of legal documents using LLMs, this study enables a path forward for automated large-scale energy policy research.