 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Frequency Scattering Accurately Models Auditory Similarities Between Instrumental Playing Techniques
Jul 21, 2020


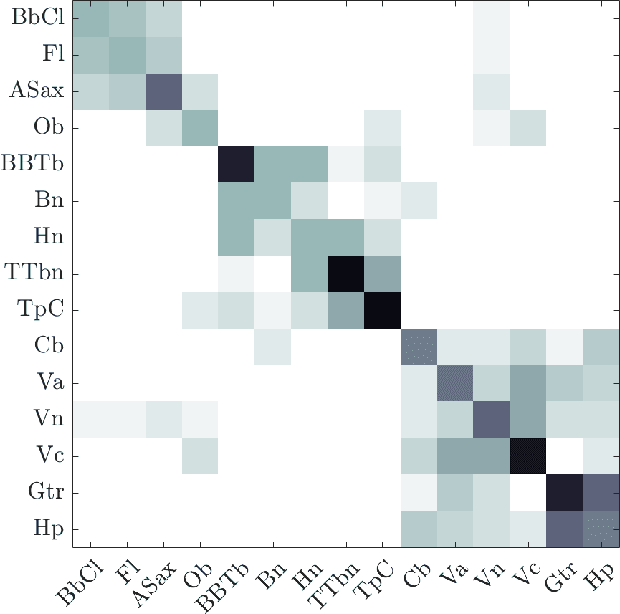
Instrumental playing techniques such as vibratos, glissandos, and trills often denote musical expressivity, both in classical and folk contexts. However, most existing approaches to music similarity retrieval fail to describe timbre beyond the so-called ``ordinary'' technique, use instrument identity as a proxy for timbre quality, and do not allow for customization to the perceptual idiosyncrasies of a new subject. In this article, we ask 31 human subjects to organize 78 isolated notes into a set of timbre clusters. Analyzing their responses suggests that timbre perception operates within a more flexible taxonomy than those provided by instruments or playing techniques alone. In addition, we propose a machine listening model to recover the cluster graph of auditory similarities across instruments, mutes, and techniques. Our model relies on joint time--frequency scattering features to extract spectrotemporal modulations as acoustic features. Furthermore, it minimizes triplet loss in the cluster graph by means of the large-margin nearest neighbor (LMNN) metric learning algorithm. Over a dataset of 9346 isolated notes, we report a state-of-the-art average precision at rank five (AP@5) of $99.0\%\pm1$. An ablation study demonstrates that removing either the joint time--frequency scattering transform or the metric learning algorithm noticeably degrades performance.
Sound Event Detection in Synthetic Audio: Analysis of the DCASE 2016 Task Results
Nov 15, 2017
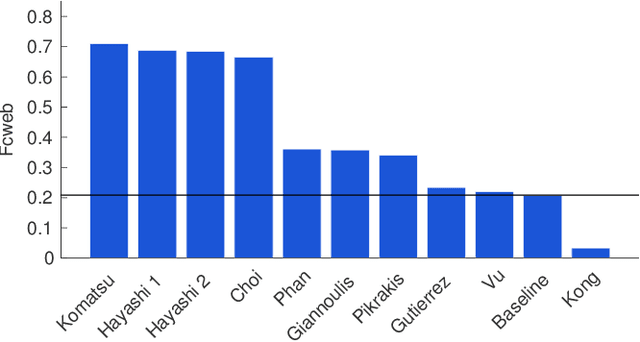
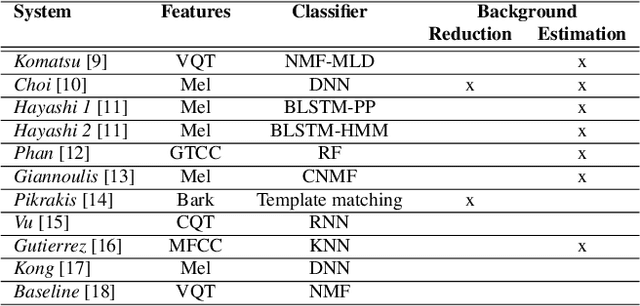

As part of the 2016 public evaluation challenge on Detection and Classification of Acoustic Scenes and Events (DCASE 2016), the second task focused on evaluating sound event detection systems using synthetic mixtures of office sounds. This task, which follows the `Event Detection - Office Synthetic' task of DCASE 2013, studies the behaviour of tested algorithms when facing controlled levels of audio complexity with respect to background noise and polyphony/density, with the added benefit of a very accurate ground truth. This paper presents the task formulation, evaluation metrics, submitted systems, and provides a statistical analysis of the results achieved, with respect to various aspects of the evaluation dataset.
The bag-of-frames approach: a not so sufficient model for urban soundscapes
Jun 12, 2016
The "bag-of-frames" approach (BOF), which encodes audio signals as the long-term statistical distribution of short-term spectral features, is commonly regarded as an effective and sufficient way to represent environmental sound recordings (soundscapes) since its introduction in an influential 2007 article. The present paper describes a concep-tual replication of this seminal article using several new soundscape datasets, with results strongly questioning the adequacy of the BOF approach for the task. We show that the good accuracy originally re-ported with BOF likely result from a particularly thankful dataset with low within-class variability, and that for more realistic datasets, BOF in fact does not perform significantly better than a mere one-point av-erage of the signal's features. Soundscape modeling, therefore, may not be the closed case it was once thought to be. Progress, we ar-gue, could lie in reconsidering the problem of considering individual acoustical events within each soundscape.
An evaluation framework for event detection using a morphological model of acoustic scenes
Jan 31, 2015
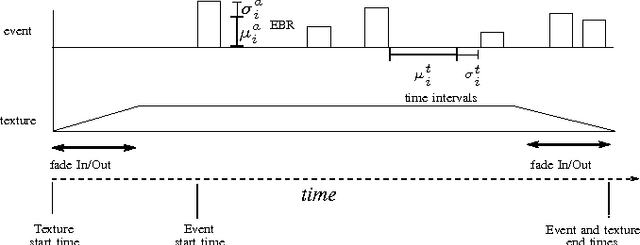


This paper introduces a model of environmental acoustic scenes which adopts a morphological approach by ab-stracting temporal structures of acoustic scenes. To demonstrate its potential, this model is employed to evaluate the performance of a large set of acoustic events detection systems. This model allows us to explicitly control key morphological aspects of the acoustic scene and isolate their impact on the performance of the system under evaluation. Thus, more information can be gained on the behavior of evaluated systems, providing guidance for further improvements. The proposed model is validated using submitted systems from the IEEE DCASE Challenge; results indicate that the proposed scheme is able to successfully build datasets useful for evaluating some aspects the performance of event detection systems, more particularly their robustness to new listening conditions and the increasing level of background sounds.