 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepPeep: Exploiting Design Ramifications to Decipher the Architecture of Compact DNNs
Jul 30, 2020
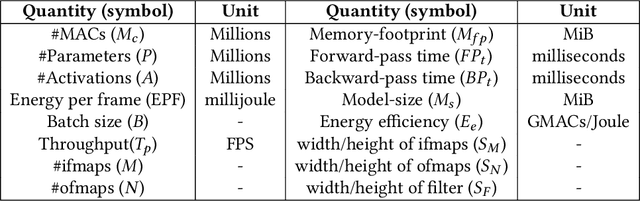

The remarkable predictive performance of deep neural networks (DNNs) has led to their adoption in service domains of unprecedented scale and scope. However, the widespread adoption and growing commercialization of DNNs have underscored the importance of intellectual property (IP) protection. Devising techniques to ensure IP protection has become necessary due to the increasing trend of outsourcing the DNN computations on the untrusted accelerators in cloud-based services. The design methodologies and hyper-parameters of DNNs are crucial information, and leaking them may cause massive economic loss to the organization. Furthermore, the knowledge of DNN's architecture can increase the success probability of an adversarial attack where an adversary perturbs the inputs and alter the prediction. In this work, we devise a two-stage attack methodology "DeepPeep" which exploits the distinctive characteristics of design methodologies to reverse-engineer the architecture of building blocks in compact DNNs. We show the efficacy of "DeepPeep" on P100 and P4000 GPUs. Additionally, we propose intelligent design maneuvering strategies for thwarting IP theft through the DeepPeep attack and proposed "Secure MobileNet-V1". Interestingly, compared to vanilla MobileNet-V1, secure MobileNet-V1 provides a significant reduction in inference latency ($\approx$60%) and improvement in predictive performance ($\approx$2%) with very-low memory and computation overheads.
The Ramifications of Making Deep Neural Networks Compact
Jun 26, 2020


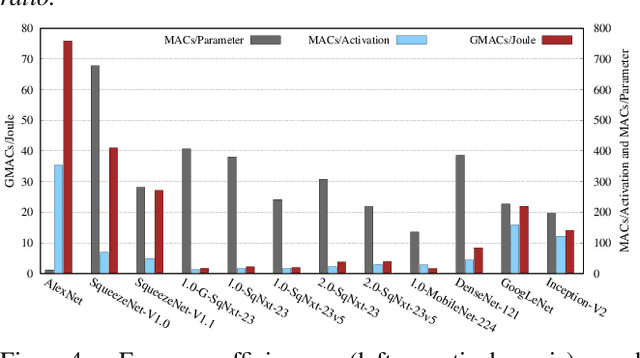
The recent trend in deep neural networks (DNNs) research is to make the networks more compact. The motivation behind designing compact DNNs is to improve energy efficiency since by virtue of having lower memory footprint, compact DNNs have lower number of off-chip accesses which improves energy efficiency. However, we show that making DNNs compact has indirect and subtle implications which are not well-understood. Reducing the number of parameters in DNNs increases the number of activations which, in turn, increases the memory footprint. We evaluate several recently-proposed compact DNNs on Tesla P100 GPU and show that their "activations to parameters ratio" ranges between 1.4 to 32.8. Further, the "memory-footprint to model size ratio" ranges between 15 to 443. This shows that a higher number of activations causes large memory footprint which increases on-chip/off-chip data movements. Furthermore, these parameter-reducing techniques reduce the arithmetic intensity which increases on-chip/off-chip memory bandwidth requirement. Due to these factors, the energy efficiency of compact DNNs may be significantly reduced which is against the original motivation for designing compact DNNs.
* Accepted as a conference paper in 2019 32nd International Conference on VLSI Design and 2019 18th International Conference on Embedded Systems (VLSID)