 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Quantifying Sentiments of Financial News -- Are We Doing the Right Things?
Dec 21, 2023Typical investors start off the day by going through the daily news to get an intuition about the performance of the market. The speculations based on the tone of the news ultimately shape their responses towards the market. Today, computers are being trained to compute the news sentiment so that it can be used as a variable to predict stock market movements and returns. Some researchers have even developed news-based market indices to forecast stock market returns. Majority of the research in the field of news sentiment analysis has focussed on using libraries like Vader, Loughran-McDonald (LM), Harvard IV and Pattern. However, are the popular approaches for measuring financial news sentiment really approaching the problem of sentiment analysis correctly? Our experiments suggest that measuring sentiments using these libraries, especially for financial news, fails to depict the true picture and hence may not be very reliable. Therefore, the question remains: What is the most effective and accurate approach to measure financial news sentiment? Our paper explores these questions and attempts to answer them through SENTInews: a one-of-its-kind financial news sentiment analyzer customized to the Indian context
Robust Portfolio Design and Stock Price Prediction Using an Optimized LSTM Model
Mar 02, 2022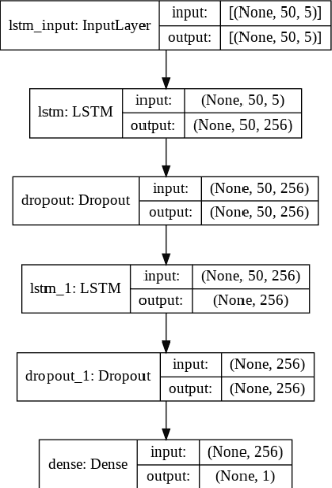
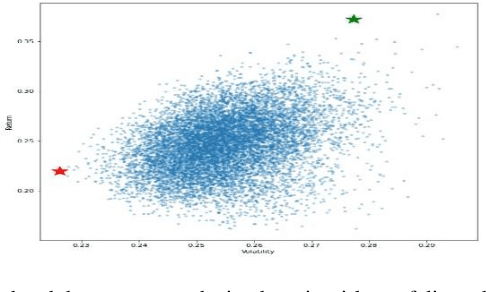

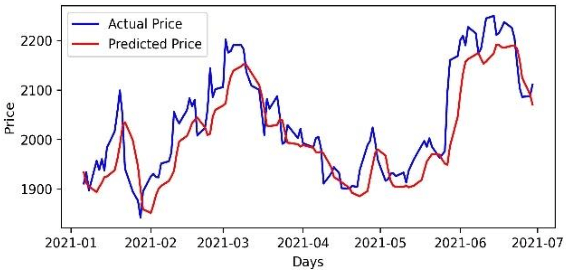
Accurate prediction of future prices of stocks is a difficult task to perform. Even more challenging is to design an optimized portfolio with weights allocated to the stocks in a way that optimizes its return and the risk. This paper presents a systematic approach towards building two types of portfolios, optimum risk, and eigen, for four critical economic sectors of India. The prices of the stocks are extracted from the web from Jan 1, 2016, to Dec 31, 2020. Sector-wise portfolios are built based on their ten most significant stocks. An LSTM model is also designed for predicting future stock prices. Six months after the construction of the portfolios, i.e., on Jul 1, 2021, the actual returns and the LSTM-predicted returns for the portfolios are computed. A comparison of the predicted and the actual returns indicate a high accuracy level of the LSTM model.
An Algorithm for Recommending Groceries Based on an Item Ranking Method
May 03, 2021
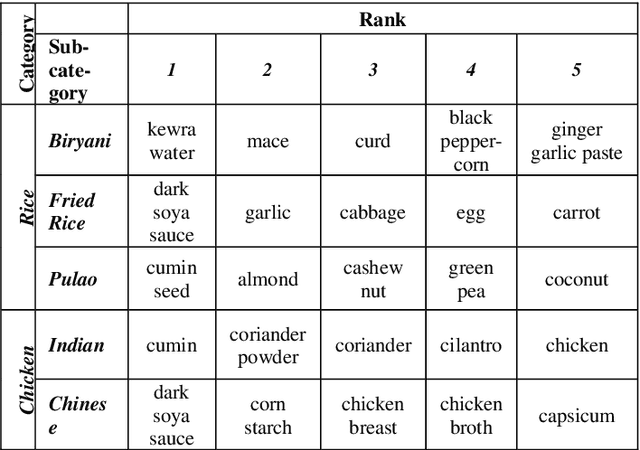
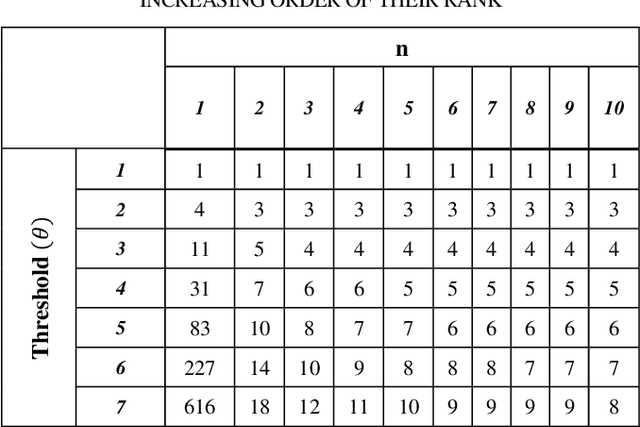
This research proposes a new recommender system algorithm for online grocery shopping. The algorithm is based on the perspective that, since the grocery items are usually bought in bulk, a grocery recommender system should be capable of recommending the items in bulk. The algorithm figures out the possible dishes a user may cook based on the items added to the basket and recommends the ingredients accordingly. Our algorithm does not depend on the user ratings. Customers usually do not have the patience to rate the groceries they purchase. Therefore, algorithms that are not dependent on user ratings need to be designed. Instead of using a brute force search, this algorithm limits the search space to a set of only a few probably food categories. Each food category consists of several food subcategories. For example, "fried rice" and "biryani" are food subcategories that belong to the food category "rice". For each food category, items are ranked according to how well they can differentiate a food subcategory. To each food subcategory in the activated search space, this algorithm attaches a score. The score is calculated based on the rank of the items added to the basket. Once the score exceeds a threshold value, its corresponding subcategory gets activated. The algorithm then uses a basket-to-recipe similarity measure to identify the best recipe matches within the activated subcategories only. This reduces the search space to a great extent. We may argue that this algorithm is similar to the content-based recommender system in some sense, but it does not suffer from the limitations like limited content, over-specialization, or the new user problem.