 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast, Precise Myelin Water Quantification using DESS MRI and Kernel Learning
Sep 24, 2018
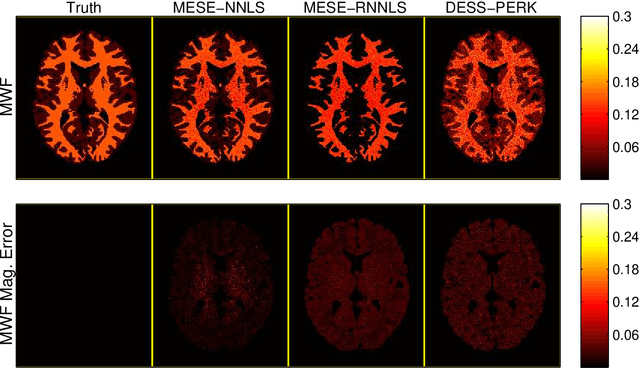
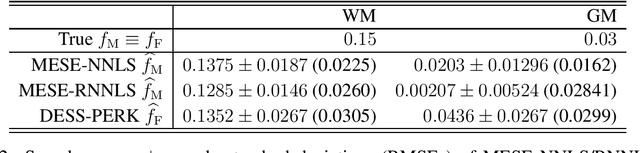
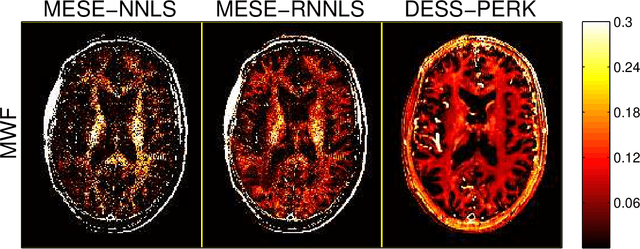
Purpose: To investigate the feasibility of myelin water content quantification using fast dual-echo steady-state (DESS) scans and machine learning with kernels. Methods: We optimized combinations of steady-state (SS) scans for precisely estimating the fast-relaxing signal fraction ff of a two-compartment signal model, subject to a scan time constraint. We estimated ff from the optimized DESS acquisition using a recently developed method for rapid parameter estimation via regression with kernels (PERK). We compared DESS PERK ff estimates to conventional myelin water fraction (MWF) estimates from a longer multi-echo spin-echo (MESE) acquisition in simulation, in vivo, and ex vivo studies. Results: Simulations demonstrate that DESS PERK ff estimators and MESE MWF estimators achieve comparable error levels. In vivo and ex vivo experiments demonstrate that MESE MWF and DESS PERK ff estimates are quantitatively comparable measures of WM myelin water content. To our knowledge, these experiments are the first to demonstrate myelin water images from a SS acquisition that are quantitatively similar to conventional MESE MWF images. Conclusion: Combinations of fast DESS scans can be designed to enable precise ff estimation. PERK is well-suited for ff estimation. DESS PERK ff and MESE MWF estimates are quantitatively similar measures of WM myelin water content.
Dictionary-Free MRI PERK: Parameter Estimation via Regression with Kernels
Oct 06, 2017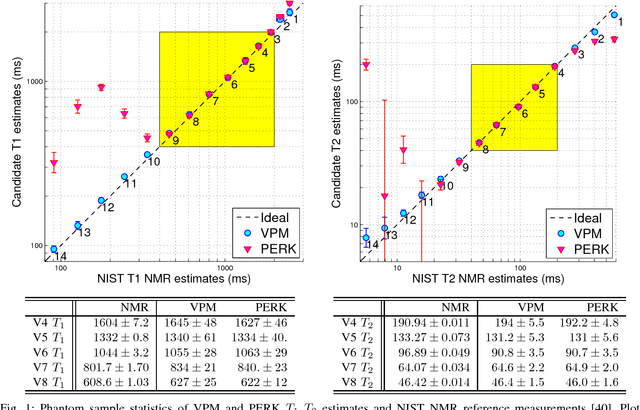
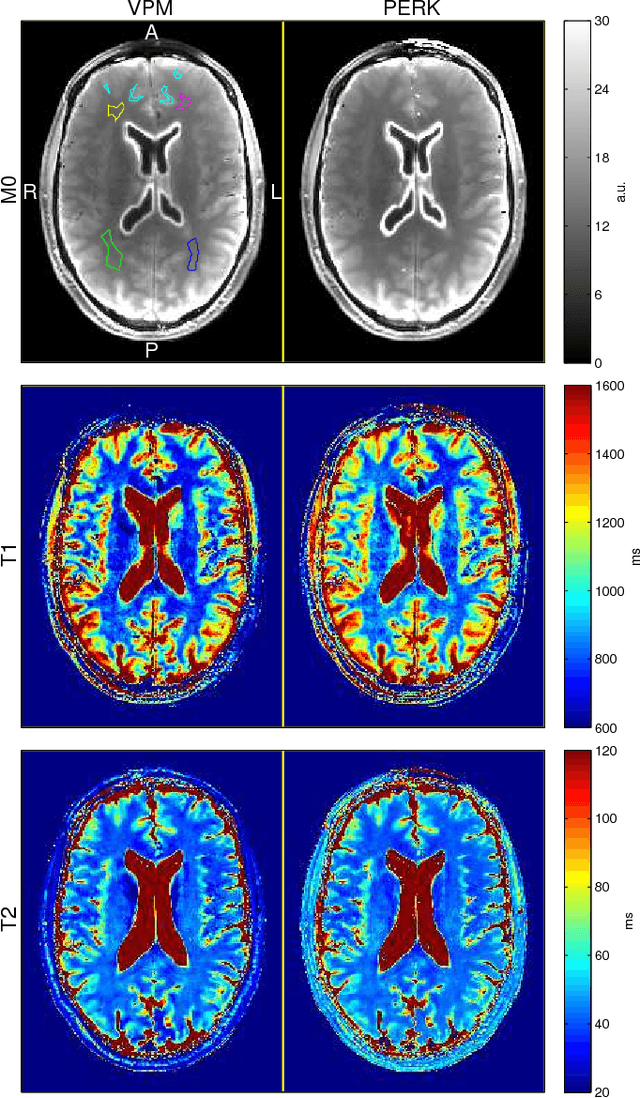

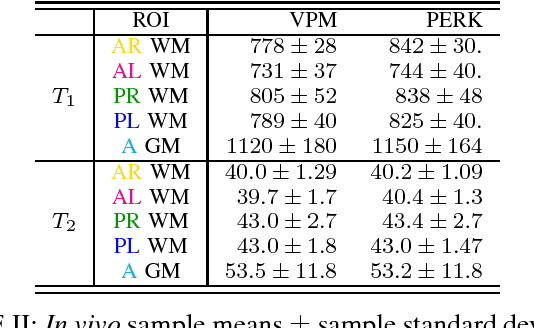
This paper introduces a fast, general method for dictionary-free parameter estimation in quantitative magnetic resonance imaging (QMRI) via regression with kernels (PERK). PERK first uses prior distributions and the nonlinear MR signal model to simulate many parameter-measurement pairs. Inspired by machine learning, PERK then takes these parameter-measurement pairs as labeled training points and learns from them a nonlinear regression function using kernel functions and convex optimization. PERK admits a simple implementation as per-voxel nonlinear lifting of MRI measurements followed by linear minimum mean-squared error regression. We demonstrate PERK for $T_1,T_2$ estimation, a well-studied application where it is simple to compare PERK estimates against dictionary-based grid search estimates. Numerical simulations as well as single-slice phantom and in vivo experiments demonstrate that PERK and grid search produce comparable $T_1,T_2$ estimates in white and gray matter, but PERK is consistently at least $23\times$ faster. This acceleration factor will increase by several orders of magnitude for full-volume QMRI estimation problems involving more latent parameters per voxel.