 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLIPS: Instance-Fingerprinting for LLMs via Pseudo-random Sequences
Jun 02, 2026Literature reveals that a Large Language Model's (LLM) behavior is not only conditioned by its original weights but also its instance-level parameters, such as instructional prompt, sampling configuration or quantization. A model that generates safe outputs under one configuration may produce toxic content under another. However, current LLM identification techniques (such as fingerprinting) focus on intellectual property protection, and their design favors robustness to changes in these instance-level parameters. This poses a critical challenge for AI regulation in which compliance assessments target actual deployed behaviors, not model provenance. In this paper, we introduce instance-level fingerprinting, a regulator-oriented paradigm that distinguishes configurations of the same LLM. Our method FLIPS, exploits biases in generated binary random sequences to reach 96% (closed-set) and 90% (open-set, where some targets are unknown) identification accuracy across 237 model instances, versus 35% for the adapted LLMmap baseline. This shows that instance-level fingerprinting is both necessary for regulation and practically feasible. Code available at https://github.com/GurvanR/FLIPS-LLM-Instance-Fingerprinting.
Evaluating the Label Efficiency of Contrastive Self-Supervised Learning for Multi-Resolution Satellite Imagery
Oct 13, 2022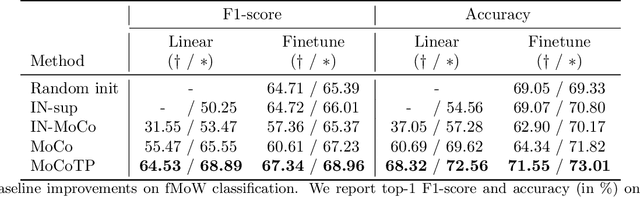
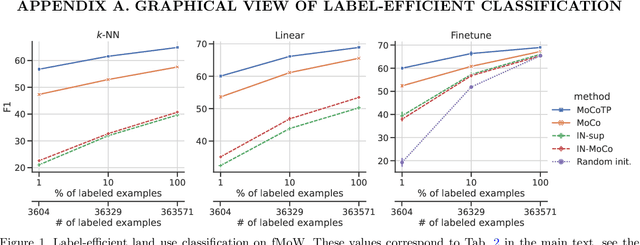
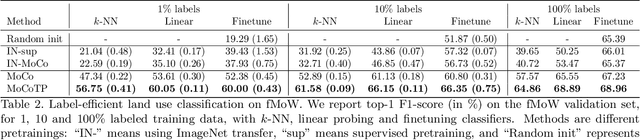
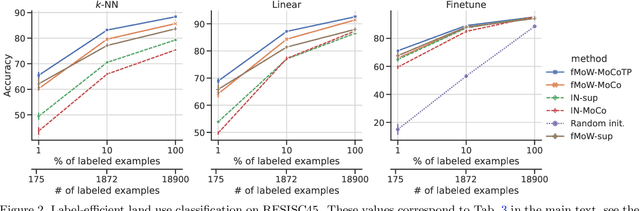
The application of deep neural networks to remote sensing imagery is often constrained by the lack of ground-truth annotations. Adressing this issue requires models that generalize efficiently from limited amounts of labeled data, allowing us to tackle a wider range of Earth observation tasks. Another challenge in this domain is developing algorithms that operate at variable spatial resolutions, e.g., for the problem of classifying land use at different scales. Recently, self-supervised learning has been applied in the remote sensing domain to exploit readily-available unlabeled data, and was shown to reduce or even close the gap with supervised learning. In this paper, we study self-supervised visual representation learning through the lens of label efficiency, for the task of land use classification on multi-resolution/multi-scale satellite images. We benchmark two contrastive self-supervised methods adapted from Momentum Contrast (MoCo) and provide evidence that these methods can be perform effectively given little downstream supervision, where randomly initialized networks fail to generalize. Moreover, they outperform out-of-domain pretraining alternatives. We use the large-scale fMoW dataset to pretrain and evaluate the networks, and validate our observations with transfer to the RESISC45 dataset.
Improving performance of aircraft detection in satellite imagery while limiting the labelling effort: Hybrid active learning
Feb 10, 2022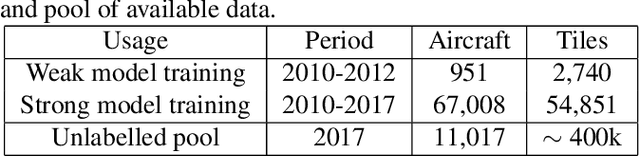
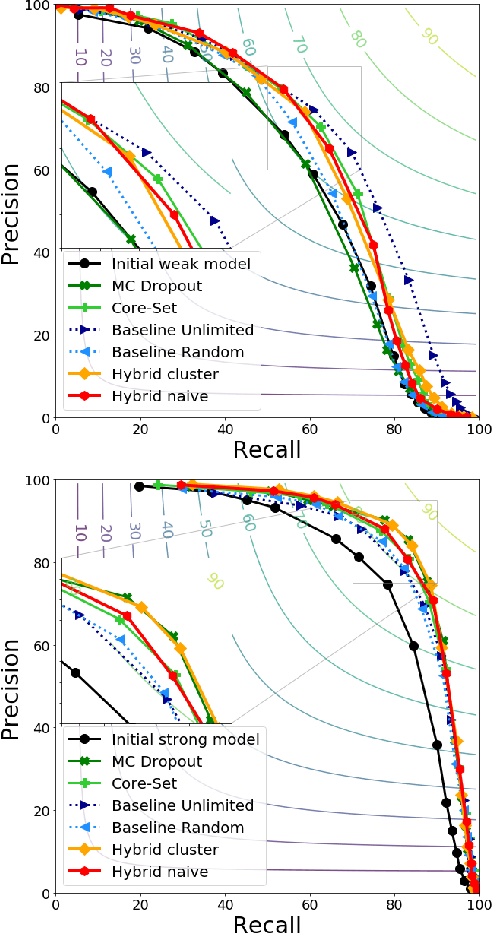
The earth observation industry provides satellite imagery with high spatial resolution and short revisit time. To allow efficient operational employment of these images, automating certain tasks has become necessary. In the defense domain, aircraft detection on satellite imagery is a valuable tool for analysts. Obtaining high performance detectors on such a task can only be achieved by leveraging deep learning and thus us-ing a large amount of labeled data. To obtain labels of a high enough quality, the knowledge of military experts is needed.We propose a hybrid clustering active learning method to select the most relevant data to label, thus limiting the amount of data required and further improving the performances. It combines diversity- and uncertainty-based active learning selection methods. For aircraft detection by segmentation, we show that this method can provide better or competitive results compared to other active learning methods.