 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Attentional Audio-Visual Fusion for Dimensional Emotion Recognition
Nov 09, 2021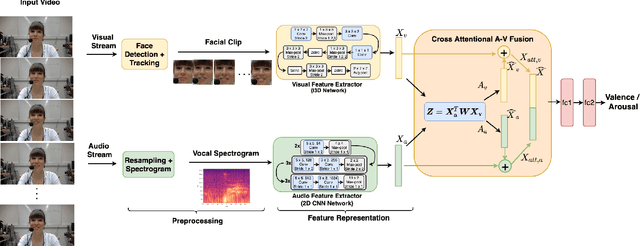
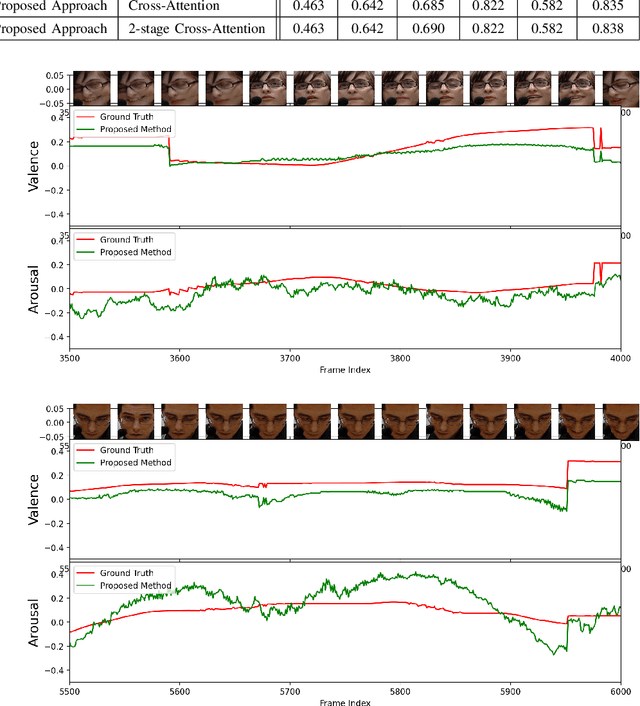
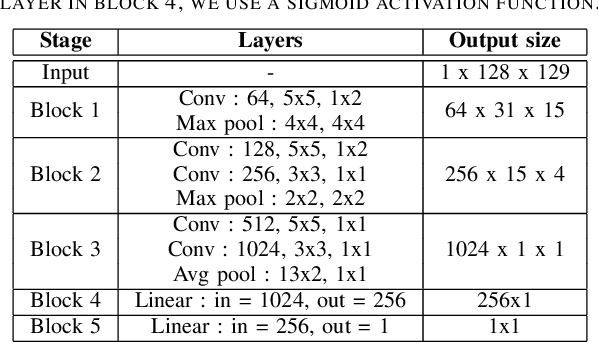
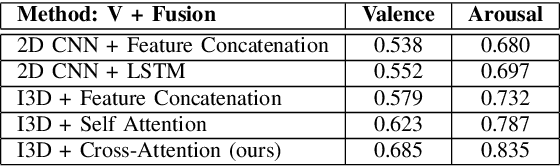
Multimodal analysis has recently drawn much interest in affective computing, since it can improve the overall accuracy of emotion recognition over isolated uni-modal approaches. The most effective techniques for multimodal emotion recognition efficiently leverage diverse and complimentary sources of information, such as facial, vocal, and physiological modalities, to provide comprehensive feature representations. In this paper, we focus on dimensional emotion recognition based on the fusion of facial and vocal modalities extracted from videos, where complex spatiotemporal relationships may be captured. Most of the existing fusion techniques rely on recurrent networks or conventional attention mechanisms that do not effectively leverage the complimentary nature of audio-visual (A-V) modalities. We introduce a cross-attentional fusion approach to extract the salient features across A-V modalities, allowing for accurate prediction of continuous values of valence and arousal. Our new cross-attentional A-V fusion model efficiently leverages the inter-modal relationships. In particular, it computes cross-attention weights to focus on the more contributive features across individual modalities, and thereby combine contributive feature representations, which are then fed to fully connected layers for the prediction of valence and arousal. The effectiveness of the proposed approach is validated experimentally on videos from the RECOLA and Fatigue (private) data-sets. Results indicate that our cross-attentional A-V fusion model is a cost-effective approach that outperforms state-of-the-art fusion approaches. Code is available: \url{https://github.com/praveena2j/Cross-Attentional-AV-Fusion}
Weakly Supervised Learning for Facial Behavior Analysis : A Review
Jan 25, 2021
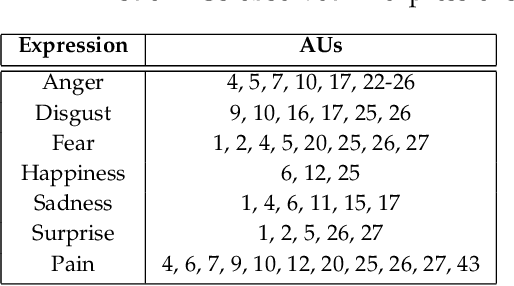

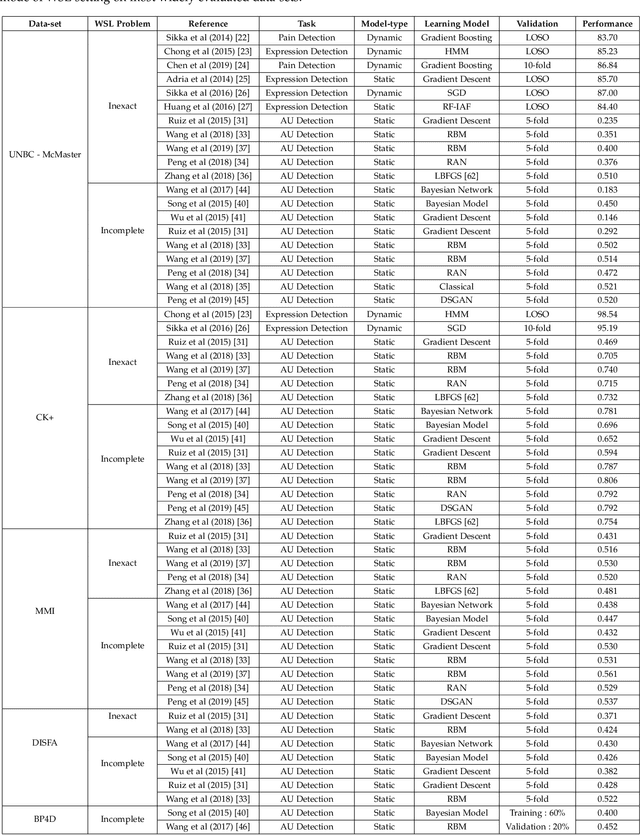
In the recent years, there has been a shift in facial behavior analysis from the laboratory-controlled conditions to the challenging in-the-wild conditions due to the superior performance of deep learning based approaches for many real world applications.However, the performance of deep learning approaches relies on the amount of training data. One of the major problems with data acquisition is the requirement of annotations for large amount of training data. Labeling process of huge training data demands lot of human support with strong domain expertise for facial expressions or action units, which is difficult to obtain in real-time environments.Moreover, labeling process is highly vulnerable to ambiguity of expressions or action units, especially for intensities due to the bias induced by the domain experts. Therefore, there is an imperative need to address the problem of facial behavior analysis with weak annotations. In this paper, we provide a comprehensive review of weakly supervised learning (WSL) approaches for facial behavior analysis with both categorical as well as dimensional labels along with the challenges and potential research directions associated with it. First, we introduce various types of weak annotations in the context of facial behavior analysis and the corresponding challenges associated with it. We then systematically review the existing state-of-the-art approaches and provide a taxonomy of these approaches along with their insights and limitations. In addition, widely used data-sets in the reviewed literature and the performance of these approaches along with evaluation principles are summarized. Finally, we discuss the remaining challenges and opportunities along with the potential research directions in order to apply facial behavior analysis with weak labels in real life situations.
Deep DA for Ordinal Regression of Pain Intensity Estimation Using Weakly-Labeled Videos
Oct 28, 2020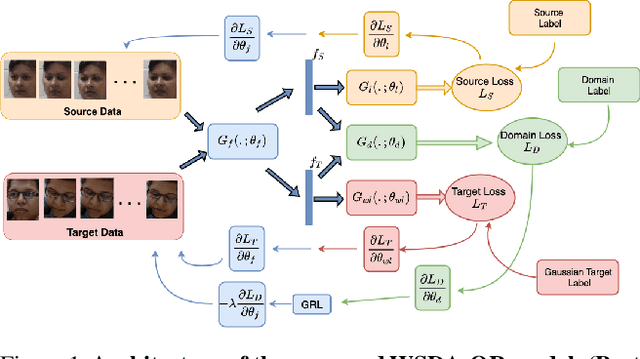
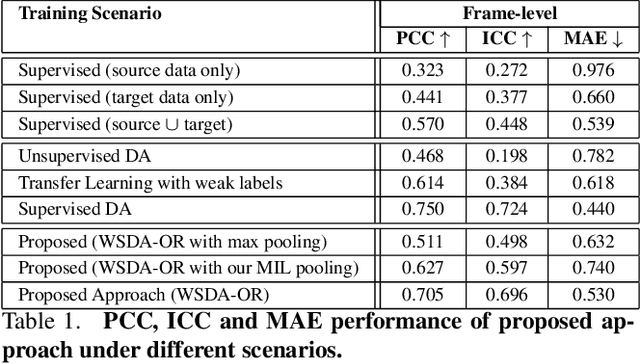
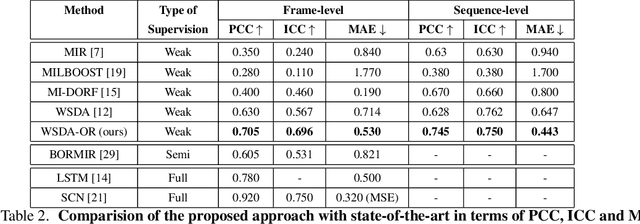
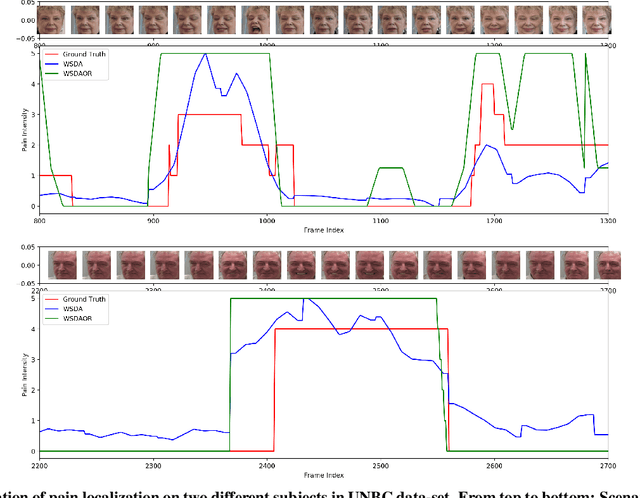
Automatic estimation of pain intensity from facial expressions in videos has an immense potential in health care applications. However, domain adaptation (DA) is needed to alleviate the problem of domain shifts that typically occurs between video data captured in source and target do-mains. Given the laborious task of collecting and annotating videos, and the subjective bias due to ambiguity among adjacent intensity levels, weakly-supervised learning (WSL)is gaining attention in such applications. Yet, most state-of-the-art WSL models are typically formulated as regression problems, and do not leverage the ordinal relation between intensity levels, nor the temporal coherence of multiple consecutive frames. This paper introduces a new deep learn-ing model for weakly-supervised DA with ordinal regression(WSDA-OR), where videos in target domain have coarse la-bels provided on a periodic basis. The WSDA-OR model enforces ordinal relationships among the intensity levels as-signed to the target sequences, and associates multiple relevant frames to sequence-level labels (instead of a single frame). In particular, it learns discriminant and domain-invariant feature representations by integrating multiple in-stance learning with deep adversarial DA, where soft Gaussian labels are used to efficiently represent the weak ordinal sequence-level labels from the target domain. The proposed approach was validated on the RECOLA video dataset as fully-labeled source domain, and UNBC-McMaster video data as weakly-labeled target domain. We have also validated WSDA-OR on BIOVID and Fatigue (private) datasets for sequence level estimation. Experimental results indicate that our approach can provide a significant improvement over the state-of-the-art models, allowing to achieve a greater localization accuracy.
Deep Domain Adaptation for Ordinal Regression of Pain Intensity Estimation Using Weakly-Labelled Videos
Aug 13, 2020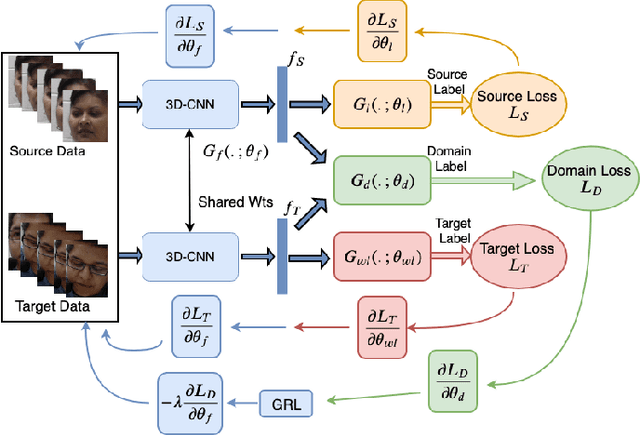
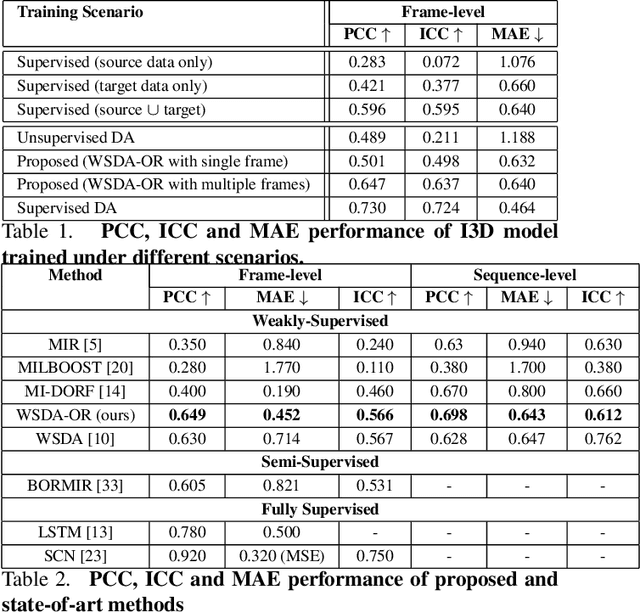
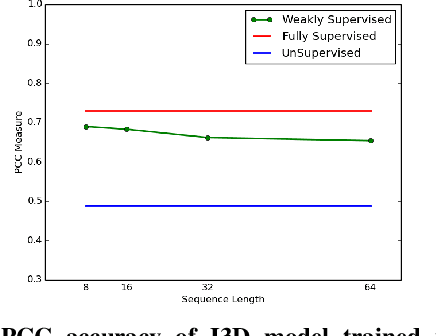
Predicting the level of facial expression intensities based on videos allow capturing a representation of affect, which has many potential applications such as pain localisation, depression detection, etc. However, state-of-the-art DL(DL) models to predict these levels are typically formulated regression problems, and do not leverage the data distribution, nor the ordinal relationship between levels. This translates to a limited robustness to noisy and uncertain labels. Moreover, annotating expression intensity levels for video frames is a costly undertaking, involving considerable labor by domain experts, and the labels are vulnerable to subjective bias due to ambiguity among adjacent intensity levels. This paper introduces a DL model for weakly-supervised domain adaptation with ordinal regression (WSDA-OR), where videos in target domain have coarse labels representing of ordinal intensity levels that are provided on a periodic basis. In particular, the proposed model learn discriminant and domain-invariant representations by integrating multiple instance learning with deep adversarial domain adaptation, where an Inflated 3D CNN (I3D) is trained using fully supervised source domain videos, and weakly supervised target domain videos. The trained model is finally used to estimate the ordinal intensity levels of individual frames in the target operational domain. The proposed approach has been validated for pain intensity estimation on using RECOLA dataset as labeled source domain, and UNBC-McMaster dataset as weakly-labeled target domain. Experimental results shows significant improvement over the state-of-the-art models and achieves higher level of localization accuracy.
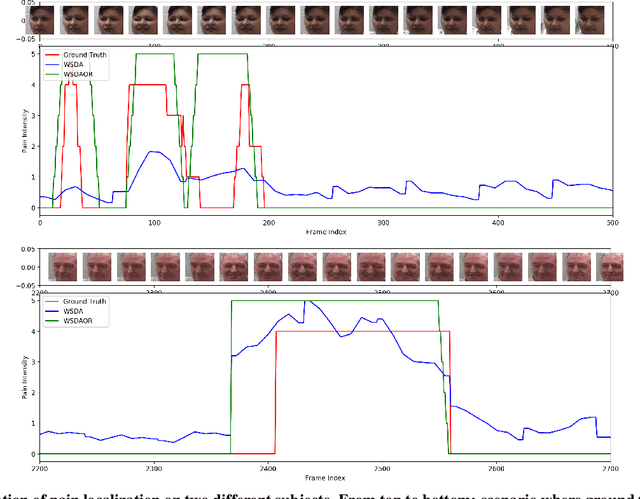
Deep Weakly-Supervised Domain Adaptation for Pain Localization in Videos
Oct 17, 2019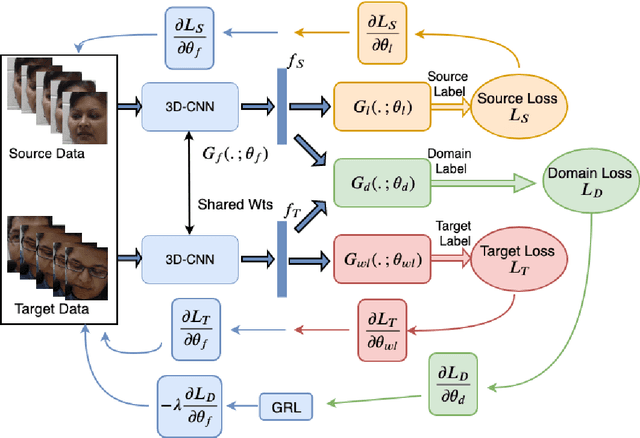


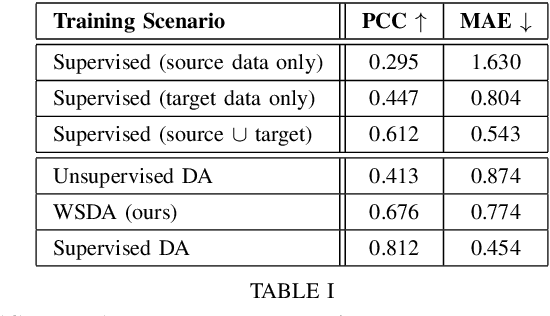
Automatic pain assessment has an important potential diagnostic value for people having difficulties in articulating their pain experiences. Facial Expression plays a crucial role as one of the dominating nonverbal channels for eliciting pain expression events, which has been widely used for estimating the pain intensity of individual videos. However, using state-of-the-art deep learning (DL) models in real-world pain estimation applications raises several challenges related to considerable subjective variations of facial expressions, operational capture conditions and lack of representative training videos with labels. Given the cost of annotating intensity levels for every video frame, a weakly-supervised domain adaptation (WSDA) technique is proposed for training DL models for spatio-temporal pain intensity estimation from videos. Deep domain adaptation to operational conditions relies on target domain videos that are weakly-labeled -- labels for pain intensity levels are provided on a periodic basis, for each video sequence. In particular, WSDA integrates multiple instance learning into an adversarial deep domain adaptation framework to train an Inflated 3D-CNN (I3D) model so that it can accurately estimate pain intensities in the target operational domain. The training mechanism leverages weak supervision loss, along with domain loss and source supervision loss for domain adaptation of I3D models. Experimental results obtained using labeled source domain videos from the RECOLA dataset and weakly-labeled target domain UNBC-McMaster videos indicate that the proposed deep WSDA approach can achieve a significantly higher level of sequence (bag)-level and frame (instance)-level pain localization accuracy than related state-of-the-art approaches.