 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Weakly-Supervised Domain Adaptation for Pain Localization in Videos
Paper and Code
Oct 17, 2019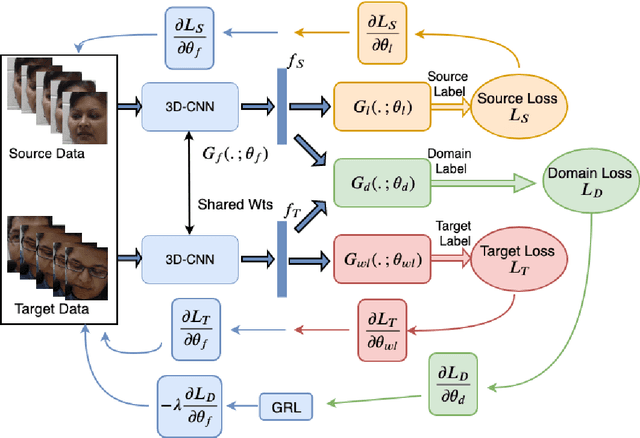


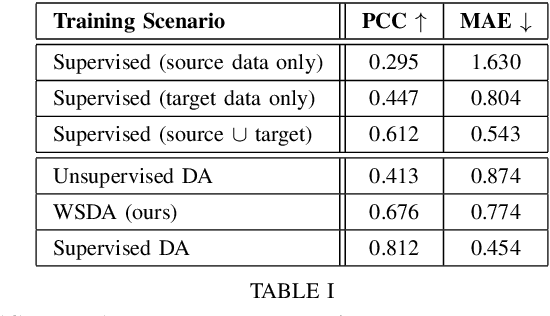
Automatic pain assessment has an important potential diagnostic value for people having difficulties in articulating their pain experiences. Facial Expression plays a crucial role as one of the dominating nonverbal channels for eliciting pain expression events, which has been widely used for estimating the pain intensity of individual videos. However, using state-of-the-art deep learning (DL) models in real-world pain estimation applications raises several challenges related to considerable subjective variations of facial expressions, operational capture conditions and lack of representative training videos with labels. Given the cost of annotating intensity levels for every video frame, a weakly-supervised domain adaptation (WSDA) technique is proposed for training DL models for spatio-temporal pain intensity estimation from videos. Deep domain adaptation to operational conditions relies on target domain videos that are weakly-labeled -- labels for pain intensity levels are provided on a periodic basis, for each video sequence. In particular, WSDA integrates multiple instance learning into an adversarial deep domain adaptation framework to train an Inflated 3D-CNN (I3D) model so that it can accurately estimate pain intensities in the target operational domain. The training mechanism leverages weak supervision loss, along with domain loss and source supervision loss for domain adaptation of I3D models. Experimental results obtained using labeled source domain videos from the RECOLA dataset and weakly-labeled target domain UNBC-McMaster videos indicate that the proposed deep WSDA approach can achieve a significantly higher level of sequence (bag)-level and frame (instance)-level pain localization accuracy than related state-of-the-art approaches.