 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Nondecomposable Data Dependent Regularizers via Lagrangian Reparameterization offers Significant Performance and Efficiency Gains
Sep 26, 2019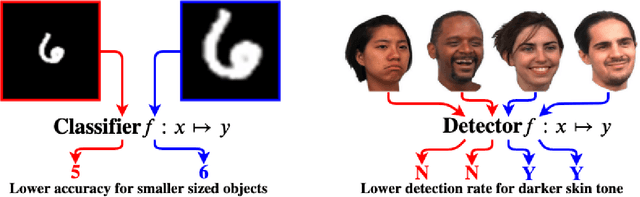
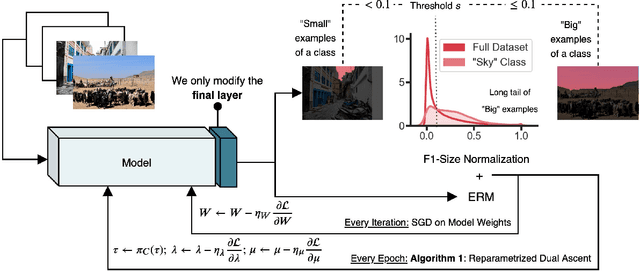
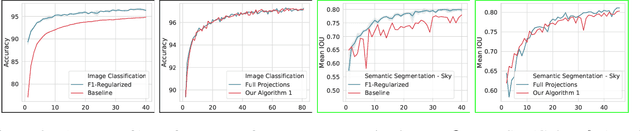

Data dependent regularization is known to benefit a wide variety of problems in machine learning. Often, these regularizers cannot be easily decomposed into a sum over a finite number of terms, e.g., a sum over individual example-wise terms. The $F_\beta$ measure, Area under the ROC curve (AUCROC) and Precision at a fixed recall (P@R) are some prominent examples that are used in many applications. We find that for most medium to large sized datasets, scalability issues severely limit our ability in leveraging the benefits of such regularizers. Importantly, the key technical impediment despite some recent progress is that, such objectives remain difficult to optimize via backpropapagation procedures. While an efficient general-purpose strategy for this problem still remains elusive, in this paper, we show that for many data-dependent nondecomposable regularizers that are relevant in applications, sizable gains in efficiency are possible with minimal code-level changes; in other words, no specialized tools or numerical schemes are needed. Our procedure involves a reparameterization followed by a partial dualization -- this leads to a formulation that has provably cheap projection operators. We present a detailed analysis of runtime and convergence properties of our algorithm. On the experimental side, we show that a direct use of our scheme significantly improves the state of the art IOU measures reported for MSCOCO Stuff segmentation dataset.