 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Specific to Generic Learned Sorted Set Dictionaries: A Theoretically Sound Paradigm Yelding Competitive Data Structural Boosters in Practice
Sep 02, 2023



This research concerns Learned Data Structures, a recent area that has emerged at the crossroad of Machine Learning and Classic Data Structures. It is methodologically important and with a high practical impact. We focus on Learned Indexes, i.e., Learned Sorted Set Dictionaries. The proposals available so far are specific in the sense that they can boost, indeed impressively, the time performance of Table Search Procedures with a sorted layout only, e.g., Binary Search. We propose a novel paradigm that, complementing known specialized ones, can produce Learned versions of any Sorted Set Dictionary, for instance, Balanced Binary Search Trees or Binary Search on layouts other that sorted, i.e., Eytzinger. Theoretically, based on it, we obtain several results of interest, such as (a) the first Learned Optimum Binary Search Forest, with mean access time bounded by the Entropy of the probability distribution of the accesses to the Dictionary; (b) the first Learned Sorted Set Dictionary that, in the Dynamic Case and in an amortized analysis setting, matches the same time bounds known for Classic Dictionaries. This latter under widely accepted assumptions regarding the size of the Universe. The experimental part, somewhat complex in terms of software development, clearly indicates the nonobvious finding that the generalization we propose can yield effective and competitive Learned Data Structural Booster, even with respect to specific benchmark models.
Learning from Data to Speed-up Sorted Table Search Procedures: Methodology and Practical Guidelines
Jul 30, 2020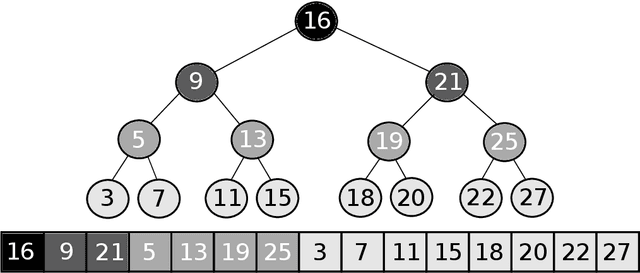
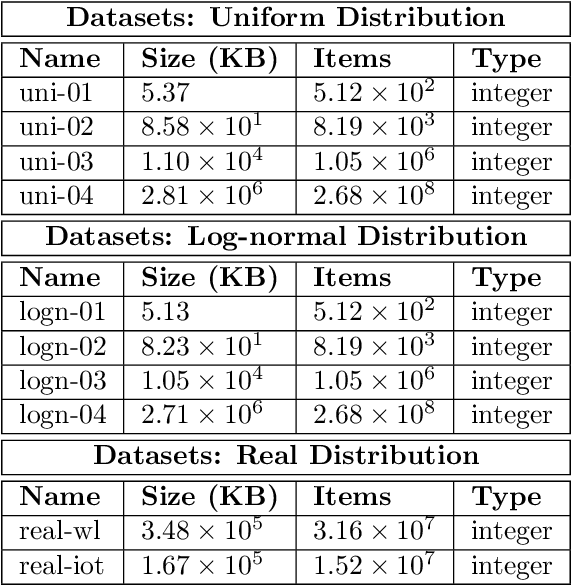
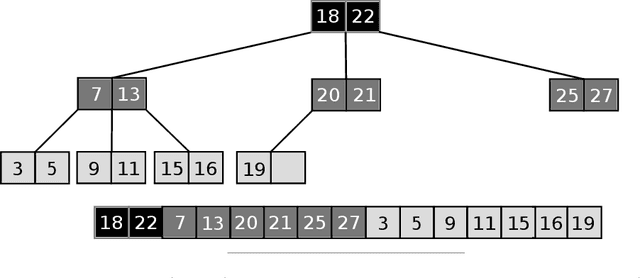

Sorted Table Search Procedures are the quintessential query-answering tool, with widespread usage that now includes also Web Applications, e.g, Search Engines (Google Chrome) and ad Bidding Systems (AppNexus). Speeding them up, at very little cost in space, is still a quite significant achievement. Here we study to what extend Machine Learning Techniques can contribute to obtain such a speed-up via a systematic experimental comparison of known efficient implementations of Sorted Table Search procedures, with different Data Layouts, and their Learned counterparts developed here. We characterize the scenarios in which those latter can be profitably used with respect to the former, accounting for both CPU and GPU computing. Our approach contributes also to the study of Learned Data Structures, a recent proposal to improve the time/space performance of fundamental Data Structures, e.g., B-trees, Hash Tables, Bloom Filters. Indeed, we also formalize an Algorithmic Paradigm of Learned Dichotomic Sorted Table Search procedures that naturally complements the Learned one proposed here and that characterizes most of the known Sorted Table Search Procedures as having a "learning phase" that approximates Simple Linear Regression.
Effectiveness of Data-Driven Induction of Semantic Spaces and Traditional Classifiers for Sarcasm Detection
Apr 15, 2019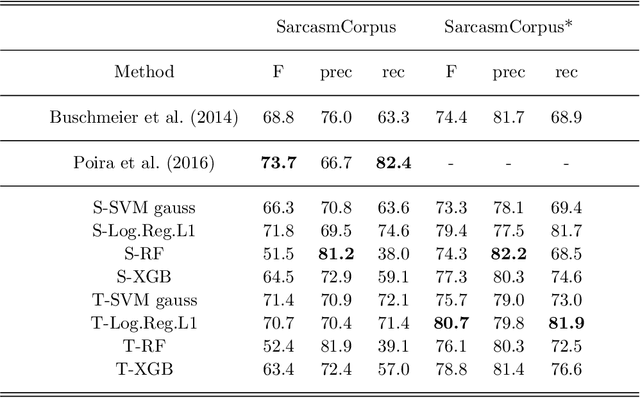

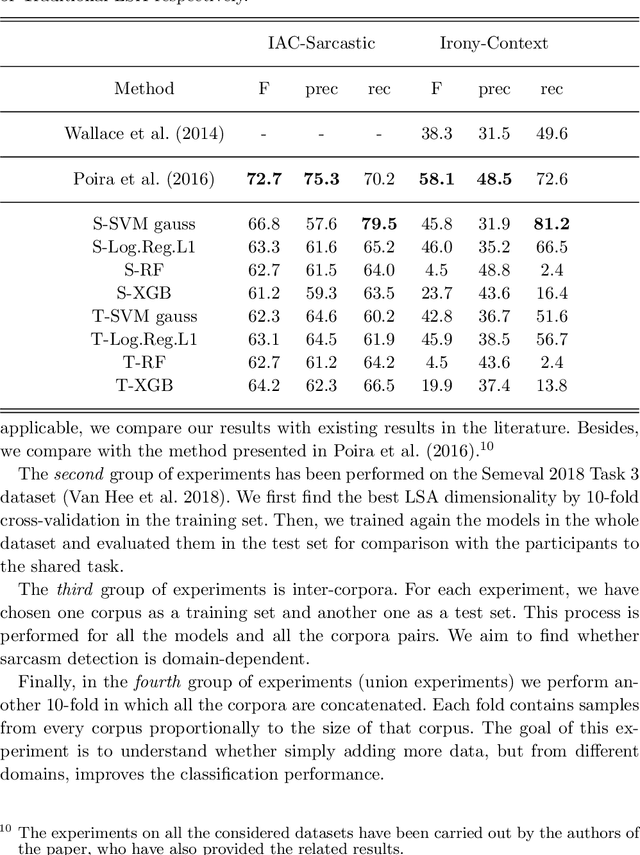

Irony and sarcasm are two complex linguistic phenomena that are widely used in everyday language and especially over the social media, but they represent two serious issues for automated text understanding. Many labelled corpora have been extracted from several sources to accomplish this task, and it seems that sarcasm is conveyed in different ways for different domains. Nonetheless, very little work has been done for comparing different methods among the available corpora. Furthermore, usually, each author collects and uses its own dataset to evaluate his own method. In this paper, we show that sarcasm detection can be tackled by applying classical machine learning algorithms to input texts sub-symbolically represented in a Latent Semantic space. The main consequence is that our studies establish both reference datasets and baselines for the sarcasm detection problem that could serve to the scientific community to test newly proposed methods.
* 37 pages, 7 figures, version 3