 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Tessellation: A Unified Approach for Video Analysis
Apr 14, 2017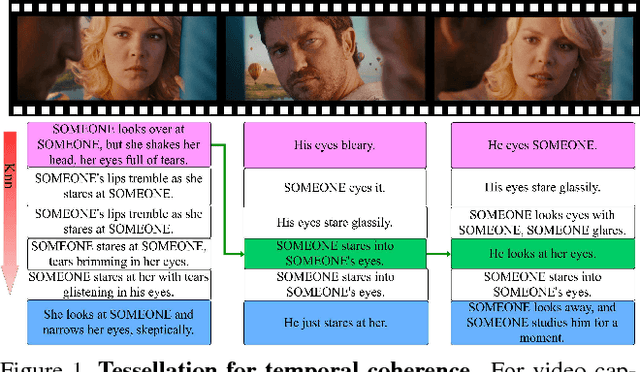
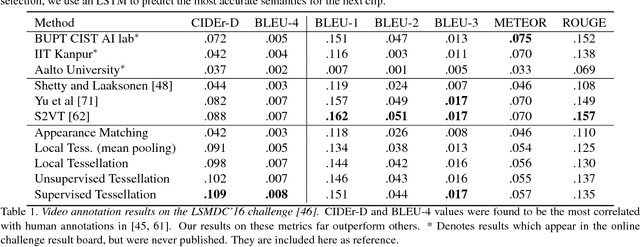

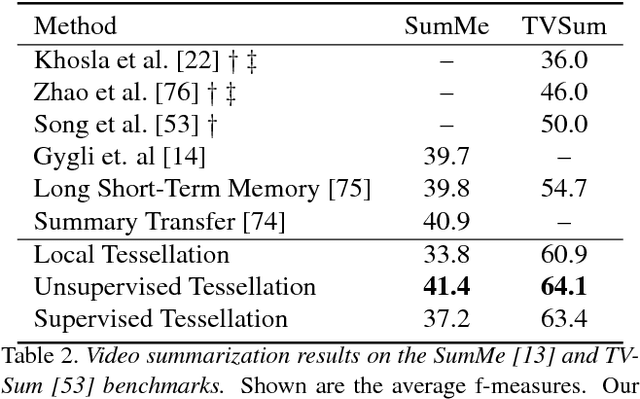
We present a general approach to video understanding, inspired by semantic transfer techniques that have been successfully used for 2D image analysis. Our method considers a video to be a 1D sequence of clips, each one associated with its own semantics. The nature of these semantics -- natural language captions or other labels -- depends on the task at hand. A test video is processed by forming correspondences between its clips and the clips of reference videos with known semantics, following which, reference semantics can be transferred to the test video. We describe two matching methods, both designed to ensure that (a) reference clips appear similar to test clips and (b), taken together, the semantics of the selected reference clips is consistent and maintains temporal coherence. We use our method for video captioning on the LSMDC'16 benchmark, video summarization on the SumMe and TVSum benchmarks, Temporal Action Detection on the Thumos2014 benchmark, and sound prediction on the Greatest Hits benchmark. Our method not only surpasses the state of the art, in four out of five benchmarks, but importantly, it is the only single method we know of that was successfully applied to such a diverse range of tasks.
The CUDA LATCH Binary Descriptor: Because Sometimes Faster Means Better
Sep 14, 2016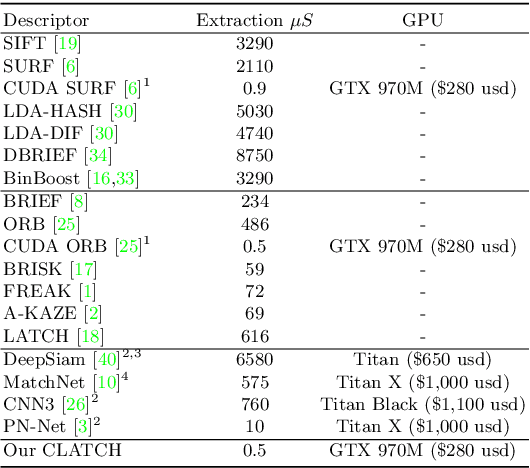

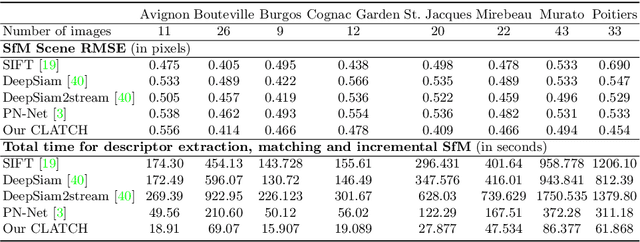
Accuracy, descriptor size, and the time required for extraction and matching are all important factors when selecting local image descriptors. To optimize over all these requirements, this paper presents a CUDA port for the recent Learned Arrangement of Three Patches (LATCH) binary descriptors to the GPU platform. The design of LATCH makes it well suited for GPU processing. Owing to its small size and binary nature, the GPU can further be used to efficiently match LATCH features. Taken together, this leads to breakneck descriptor extraction and matching speeds. We evaluate the trade off between these speeds and the quality of results in a feature matching intensive application. To this end, we use our proposed CUDA LATCH (CLATCH) to recover structure from motion (SfM), comparing 3D reconstructions and speed using different representations. Our results show that CLATCH provides high quality 3D reconstructions at fractions of the time required by other representations, with little, if any, loss of reconstruction quality.
LATCH: Learned Arrangements of Three Patch Codes
Jan 15, 2015
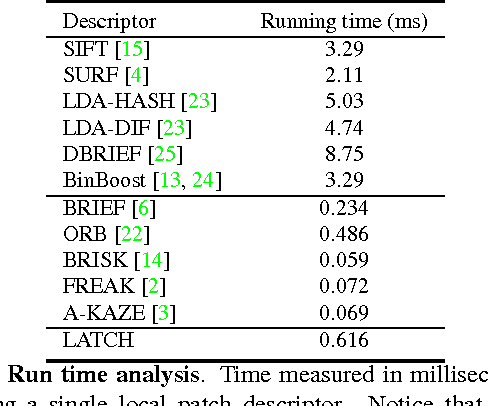
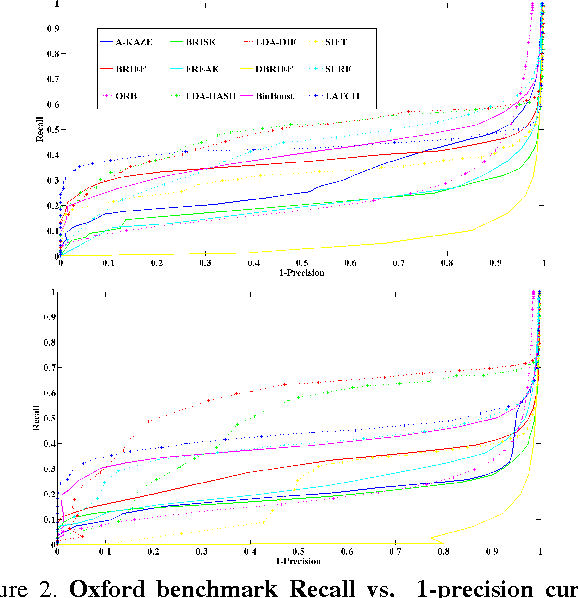
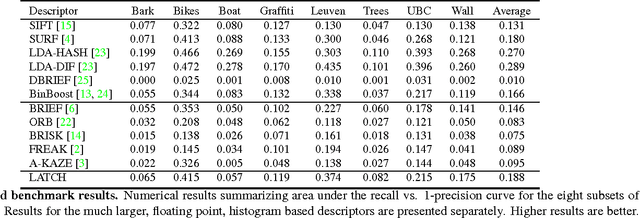
We present a novel means of describing local image appearances using binary strings. Binary descriptors have drawn increasing interest in recent years due to their speed and low memory footprint. A known shortcoming of these representations is their inferior performance compared to larger, histogram based descriptors such as the SIFT. Our goal is to close this performance gap while maintaining the benefits attributed to binary representations. To this end we propose the Learned Arrangements of Three Patch Codes descriptors, or LATCH. Our key observation is that existing binary descriptors are at an increased risk from noise and local appearance variations. This, as they compare the values of pixel pairs; changes to either of the pixels can easily lead to changes in descriptor values, hence damaging its performance. In order to provide more robustness, we instead propose a novel means of comparing pixel patches. This ostensibly small change, requires a substantial redesign of the descriptors themselves and how they are produced. Our resulting LATCH representation is rigorously compared to state-of-the-art binary descriptors and shown to provide far better performance for similar computation and space requirements.