 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient generative adversarial networks using linear additive-attention Transformers
Jan 17, 2024Although the capacity of deep generative models for image generation, such as Diffusion Models (DMs) and Generative Adversarial Networks (GANs), has dramatically improved in recent years, much of their success can be attributed to computationally expensive architectures. This has limited their adoption and use to research laboratories and companies with large resources, while significantly raising the carbon footprint for training, fine-tuning, and inference. In this work, we present LadaGAN, an efficient generative adversarial network that is built upon a novel Transformer block named Ladaformer. The main component of this block is a linear additive-attention mechanism that computes a single attention vector per head instead of the quadratic dot-product attention. We employ Ladaformer in both the generator and discriminator, which reduces the computational complexity and overcomes the training instabilities often associated with Transformer GANs. LadaGAN consistently outperforms existing convolutional and Transformer GANs on benchmark datasets at different resolutions while being significantly more efficient. Moreover, LadaGAN shows competitive performance compared to state-of-the-art multi-step generative models (e.g. DMs) using orders of magnitude less computational resources.
Trailers12k: Improving Transfer Learning with a Dual Image and Video Transformer for Multi-label Movie Trailer Genre Classification
Oct 19, 2022

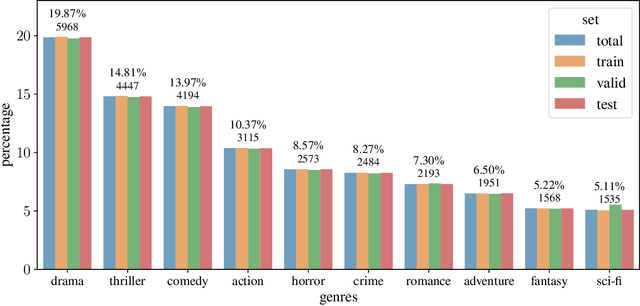
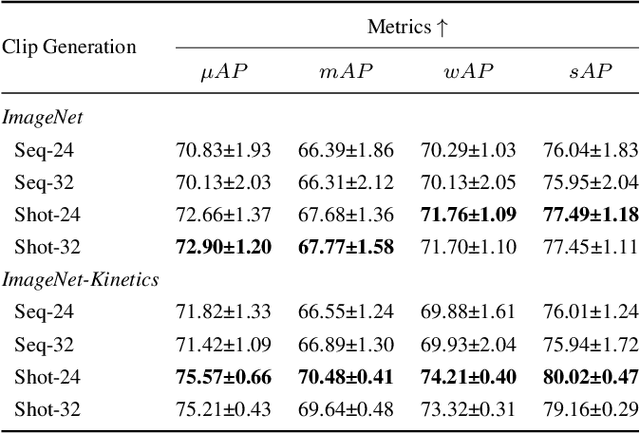
In this paper, we propose Dual Image and Video Transformer Architecture (DIViTA) for multi-label movie trailer genre classification. DIViTA performs an input adaption stage that uses shot detection to segment the trailer into highly correlated clips, providing a more cohesive input that allows to leverage pretrained ImageNet and/or Kinetics backbones. We introduce Trailers12k, a movie trailer dataset with manually verified title-trailer pairs, and present a transferability study of representations learned from ImageNet and Kinetics to Trailers12k. Our results show that DIViTA can reduce the gap between the spatio-temporal structure of the source and target datasets, thus improving transferability. Moreover, representations learned on either ImageNet or Kinetics are comparatively transferable to Trailers12k, although they provide complementary information that can be combined to improve classification performance. Interestingly, pretrained lightweight ConvNets provide competitive classification performance, while using a fraction of the computing resources compared to heavier ConvNets and Transformers.
A few filters are enough: Convolutional Neural Network for P300 Detection
Sep 16, 2019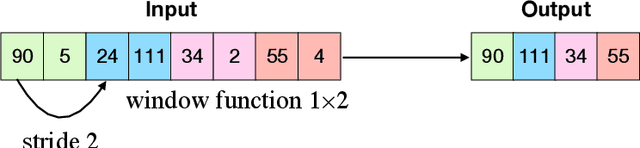

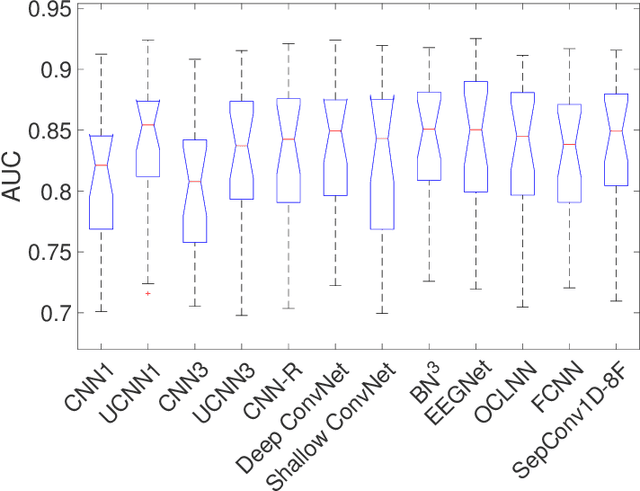
In this paper, we aim to provide elements to contribute to the discussion about the usefulness of deep CNNs with several filters to solve both within-subject and cross-subject classification for single-trial P300 detection. To that end, we present SepConv1D, a simple Convolutional Neural Network architecture consisting of a depthwise separable 1D convolutional block followed by a Sigmoid classification block. Additionally, we present a one-layer Fully-Connected Neural Network with two neurons in the hidden layer to show the unnecessary of having complex architectures to solve the problem under analysis. We compare their performances against CNN-based state-of-the-art architectures. The experiments did not show a statistically significant difference between their AUC. Moreover, SepConv1D has the lowest number of parameters of all by far. This is important because simpler, cheaper, faster and, thus, more portable devices can be built.
Topic Discovery in Massive Text Corpora Based on Min-Hashing
Jul 03, 2018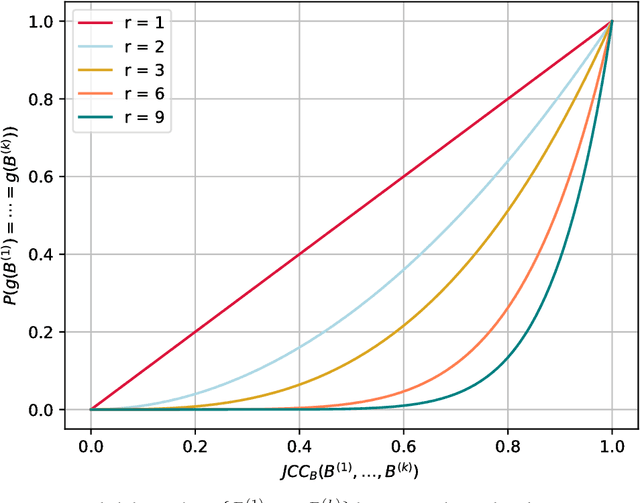

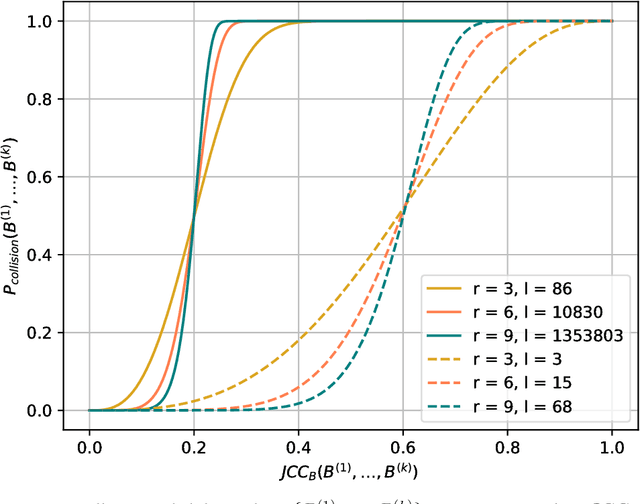
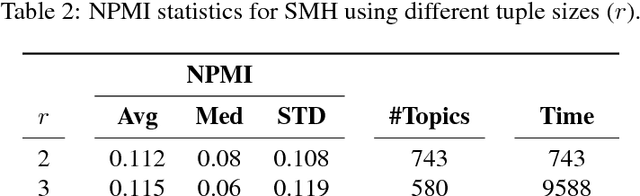
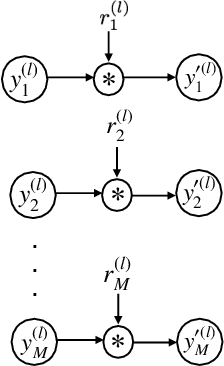
The task of discovering topics in text corpora has been dominated by Latent Dirichlet Allocation and other Topic Models for over a decade. In order to apply these approaches to massive text corpora, the vocabulary needs to be reduced considerably and large computer clusters and/or GPUs are typically required. Moreover, the number of topics must be provided beforehand but this depends on the corpus characteristics and it is often difficult to estimate, especially for massive text corpora. Unfortunately, both topic quality and time complexity are sensitive to this choice. This paper describes an alternative approach to discover topics based on Min-Hashing, which can handle massive text corpora and large vocabularies using modest computer hardware and does not require to fix the number of topics in advance. The basic idea is to generate multiple random partitions of the corpus vocabulary to find sets of highly co-occurring words, which are then clustered to produce the final topics. In contrast to probabilistic topic models where topics are distributions over the complete vocabulary, the topics discovered by the proposed approach are sets of highly co-occurring words. Interestingly, these topics underlie various thematics with different levels of granularity. An extensive qualitative and quantitative evaluation using the 20 Newsgroups (18K), Reuters (800K), Spanish Wikipedia (1M), and English Wikipedia (5M) corpora shows that the proposed approach is able to consistently discover meaningful and coherent topics. Remarkably, the time complexity of the proposed approach is linear with respect to corpus and vocabulary size; a non-parallel implementation was able to discover topics from the entire English edition of Wikipedia with over 5 million documents and 1 million words in less than 7 hours.
Contextualize, Show and Tell: A Neural Visual Storyteller
Jun 03, 2018
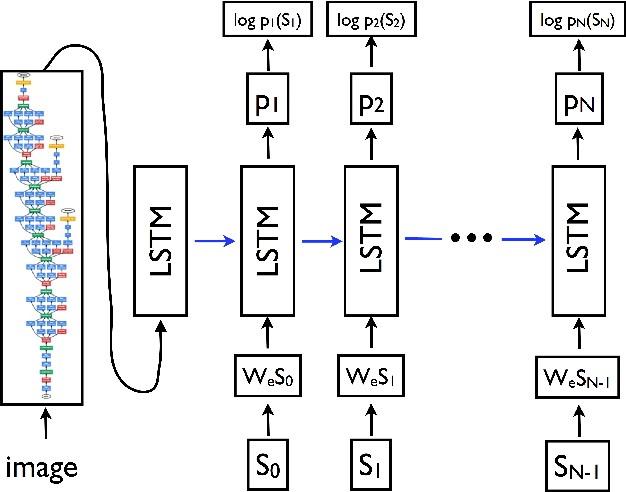

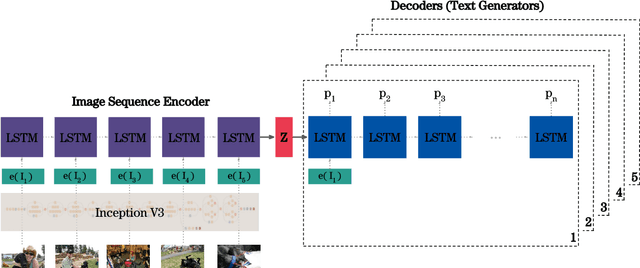
We present a neural model for generating short stories from image sequences, which extends the image description model by Vinyals et al. (Vinyals et al., 2015). This extension relies on an encoder LSTM to compute a context vector of each story from the image sequence. This context vector is used as the first state of multiple independent decoder LSTMs, each of which generates the portion of the story corresponding to each image in the sequence by taking the image embedding as the first input. Our model showed competitive results with the METEOR metric and human ratings in the internal track of the Visual Storytelling Challenge 2018.
Sampled Weighted Min-Hashing for Large-Scale Topic Mining
Sep 08, 2015
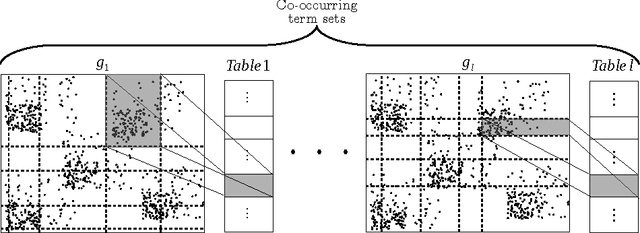
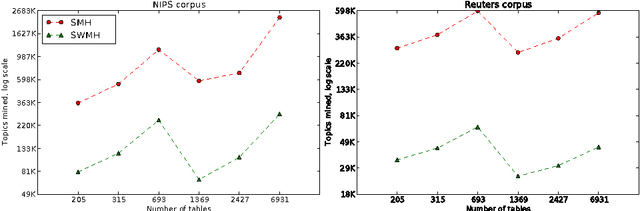
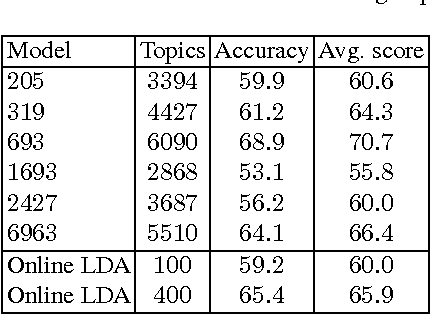
We present Sampled Weighted Min-Hashing (SWMH), a randomized approach to automatically mine topics from large-scale corpora. SWMH generates multiple random partitions of the corpus vocabulary based on term co-occurrence and agglomerates highly overlapping inter-partition cells to produce the mined topics. While other approaches define a topic as a probabilistic distribution over a vocabulary, SWMH topics are ordered subsets of such vocabulary. Interestingly, the topics mined by SWMH underlie themes from the corpus at different levels of granularity. We extensively evaluate the meaningfulness of the mined topics both qualitatively and quantitatively on the NIPS (1.7 K documents), 20 Newsgroups (20 K), Reuters (800 K) and Wikipedia (4 M) corpora. Additionally, we compare the quality of SWMH with Online LDA topics for document representation in classification.