 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Style in Generated Dialogue
Sep 22, 2020
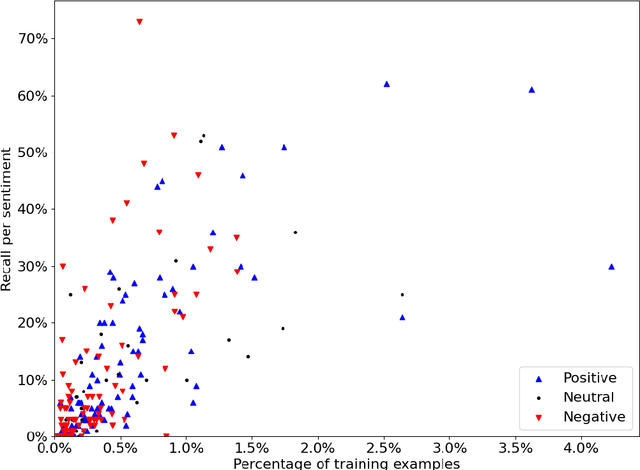
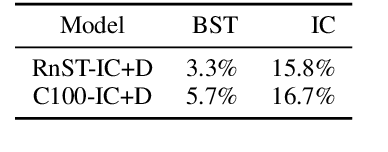
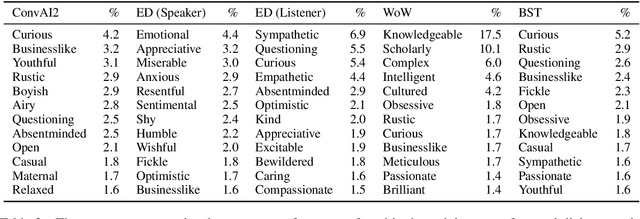
Open-domain conversation models have become good at generating natural-sounding dialogue, using very large architectures with billions of trainable parameters. The vast training data required to train these architectures aggregates many different styles, tones, and qualities. Using that data to train a single model makes it difficult to use the model as a consistent conversational agent, e.g. with a stable set of persona traits and a typical style of expression. Several architectures affording control mechanisms over generation architectures have been proposed, each with different trade-offs. However, it remains unclear whether their use in dialogue is viable, and what the trade-offs look like with the most recent state-of-the-art conversational architectures. In this work, we adapt three previously proposed controllable generation architectures to open-domain dialogue generation, controlling the style of the generation to match one among about 200 possible styles. We compare their respective performance and tradeoffs, and show how they can be used to provide insights into existing conversational datasets, and generate a varied set of styled conversation replies.
Zero-Shot Fine-Grained Style Transfer: Leveraging Distributed Continuous Style Representations to Transfer To Unseen Styles
Nov 10, 2019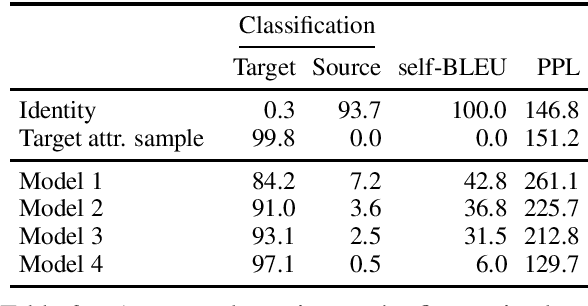



Text style transfer is usually performed using attributes that can take a handful of discrete values (e.g., positive to negative reviews). In this work, we introduce an architecture that can leverage pre-trained consistent continuous distributed style representations and use them to transfer to an attribute unseen during training, without requiring any re-tuning of the style transfer model. We demonstrate the method by training an architecture to transfer text conveying one sentiment to another sentiment, using a fine-grained set of over 20 sentiment labels rather than the binary positive/negative often used in style transfer. Our experiments show that this model can then rewrite text to match a target sentiment that was unseen during training.
Contextualize, Show and Tell: A Neural Visual Storyteller
Jun 03, 2018
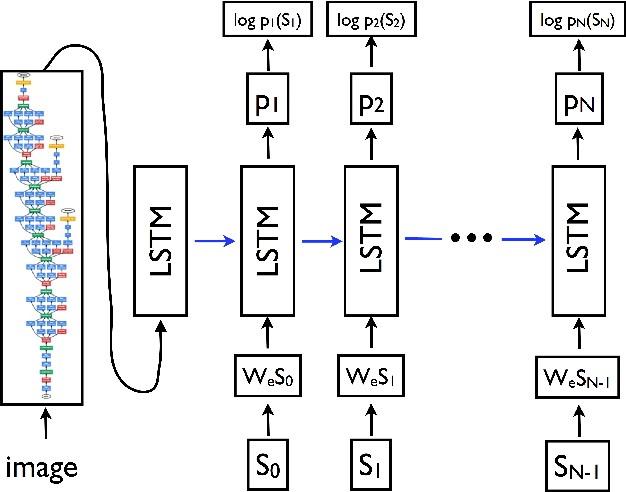

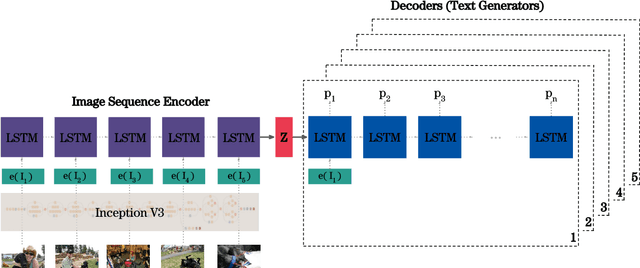
We present a neural model for generating short stories from image sequences, which extends the image description model by Vinyals et al. (Vinyals et al., 2015). This extension relies on an encoder LSTM to compute a context vector of each story from the image sequence. This context vector is used as the first state of multiple independent decoder LSTMs, each of which generates the portion of the story corresponding to each image in the sequence by taking the image embedding as the first input. Our model showed competitive results with the METEOR metric and human ratings in the internal track of the Visual Storytelling Challenge 2018.