 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrailers12k: Improving Transfer Learning with a Dual Image and Video Transformer for Multi-label Movie Trailer Genre Classification
Oct 19, 2022

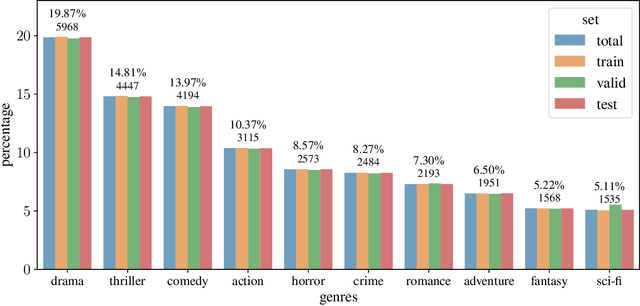
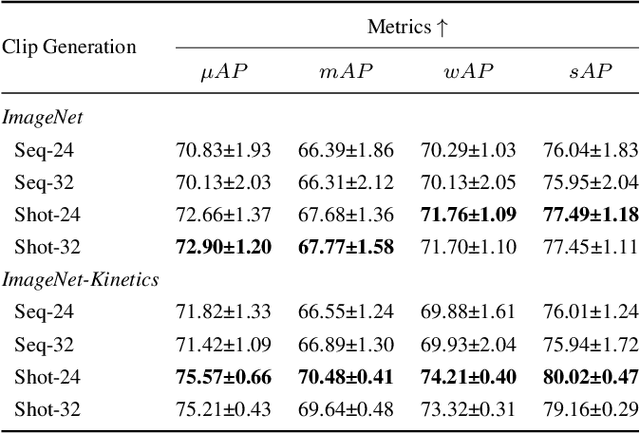
In this paper, we propose Dual Image and Video Transformer Architecture (DIViTA) for multi-label movie trailer genre classification. DIViTA performs an input adaption stage that uses shot detection to segment the trailer into highly correlated clips, providing a more cohesive input that allows to leverage pretrained ImageNet and/or Kinetics backbones. We introduce Trailers12k, a movie trailer dataset with manually verified title-trailer pairs, and present a transferability study of representations learned from ImageNet and Kinetics to Trailers12k. Our results show that DIViTA can reduce the gap between the spatio-temporal structure of the source and target datasets, thus improving transferability. Moreover, representations learned on either ImageNet or Kinetics are comparatively transferable to Trailers12k, although they provide complementary information that can be combined to improve classification performance. Interestingly, pretrained lightweight ConvNets provide competitive classification performance, while using a fraction of the computing resources compared to heavier ConvNets and Transformers.