 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating tabular datasets under differential privacy
Aug 28, 2023Machine Learning (ML) is accelerating progress across fields and industries, but relies on accessible and high-quality training data. Some of the most important datasets are found in biomedical and financial domains in the form of spreadsheets and relational databases. But this tabular data is often sensitive in nature. Synthetic data generation offers the potential to unlock sensitive data, but generative models tend to memorise and regurgitate training data, which undermines the privacy goal. To remedy this, researchers have incorporated the mathematical framework of Differential Privacy (DP) into the training process of deep neural networks. But this creates a trade-off between the quality and privacy of the resulting data. Generative Adversarial Networks (GANs) are the dominant paradigm for synthesising tabular data under DP, but suffer from unstable adversarial training and mode collapse, which are exacerbated by the privacy constraints and challenging tabular data modality. This work optimises the quality-privacy trade-off of generative models, producing higher quality tabular datasets with the same privacy guarantees. We implement novel end-to-end models that leverage attention mechanisms to learn reversible tabular representations. We also introduce TableDiffusion, the first differentially-private diffusion model for tabular data synthesis. Our experiments show that TableDiffusion produces higher-fidelity synthetic datasets, avoids the mode collapse problem, and achieves state-of-the-art performance on privatised tabular data synthesis. By implementing TableDiffusion to predict the added noise, we enabled it to bypass the challenges of reconstructing mixed-type tabular data. Overall, the diffusion paradigm proves vastly more data and privacy efficient than the adversarial paradigm, due to augmented re-use of each data batch and a smoother iterative training process.
Quantified Sleep: Machine learning techniques for observational n-of-1 studies
May 14, 2021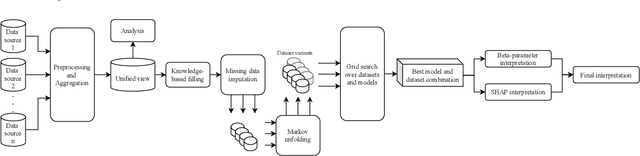
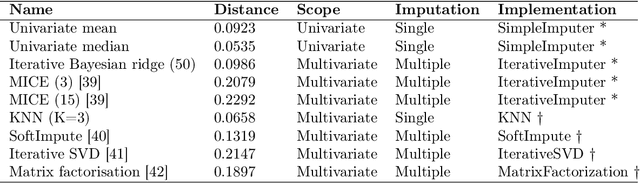
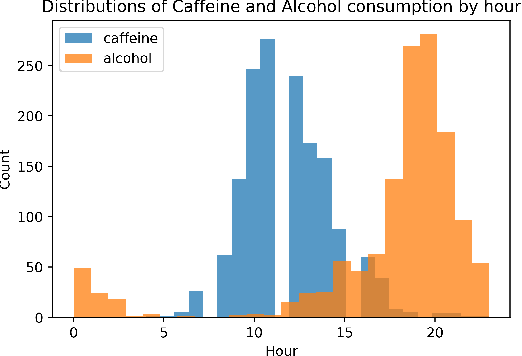
This paper applies statistical learning techniques to an observational Quantified-Self (QS) study to build a descriptive model of sleep quality. A total of 472 days of my sleep data was collected with an Oura ring and combined with lifestyle, environmental, and psychological data. Such n-of-1 QS projects pose a number of challenges: heterogeneous data sources; missing values; high dimensionality; dynamic feedback loops; human biases. This paper directly addresses these challenges with an end-to-end QS pipeline that produces robust descriptive models. Sleep quality is one of the most difficult modelling targets in QS research, due to high noise and a large number of weakly-contributing factors. Sleep quality was selected so that approaches from this paper would generalise to most other n-of-1 QS projects. Techniques are presented for combining and engineering features for the different classes of data types, sample frequencies, and schema - including event logs, weather, and geo-spatial data. Statistical analyses for outliers, normality, (auto)correlation, stationarity, and missing data are detailed, along with a proposed method for hierarchical clustering to identify correlated groups of features. The missing data was overcome using a combination of knowledge-based and statistical techniques, including several multivariate imputation algorithms. "Markov unfolding" is presented for collapsing the time series into a collection of independent observations, whilst incorporating historical information. The final model was interpreted in two ways: by inspecting the internal $\beta$-parameters, and using the SHAP framework. These two interpretation techniques were combined to produce a list of the 16 most-predictive features, demonstrating that an observational study can greatly narrow down the number of features that need to be considered when designing interventional QS studies.
Warfarin dose estimation on multiple datasets with automated hyperparameter optimisation and a novel software framework
Jul 11, 2019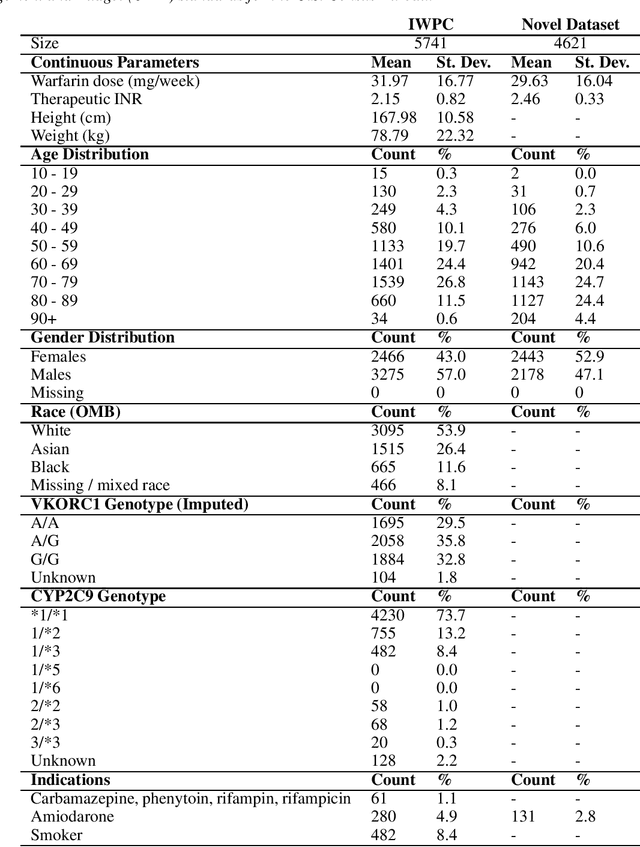

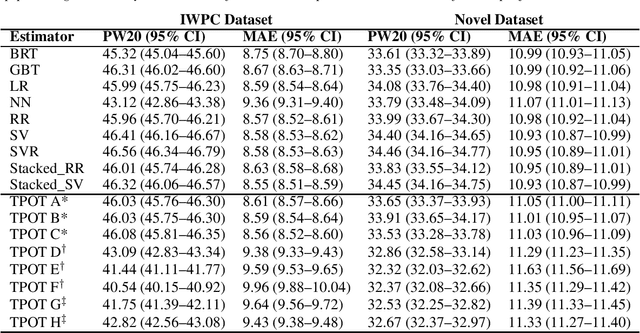
Warfarin is an effective preventative treatment for arterial and venous thromboembolism, but requires individualised dosing due to its narrow therapeutic range and high individual variation. A plethora of statistical and machine learning techniques have been demonstrated in this domain. This study evaluated the accuracy of the most promising algorithms on the International Warfarin Pharmacogenetics Consortium dataset and a novel clinical dataset of South African patients. Support vectors and linear regression were consistently amongst the top performers in both datasets and performed comparably to recent ensemble approaches. We also evaluated the use of genetic programming to design and optimise learning models without human guidance, finding that performance matched that of models hand-crafted by human experts. Finally, we present a novel software framework (warfit-learn) for standardising future research by leveraging the most successful techniques in preprocessing, imputation, and evaluation, with the goal of making results more reproducible in this domain.