 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWarfarin dose estimation on multiple datasets with automated hyperparameter optimisation and a novel software framework
Paper and Code
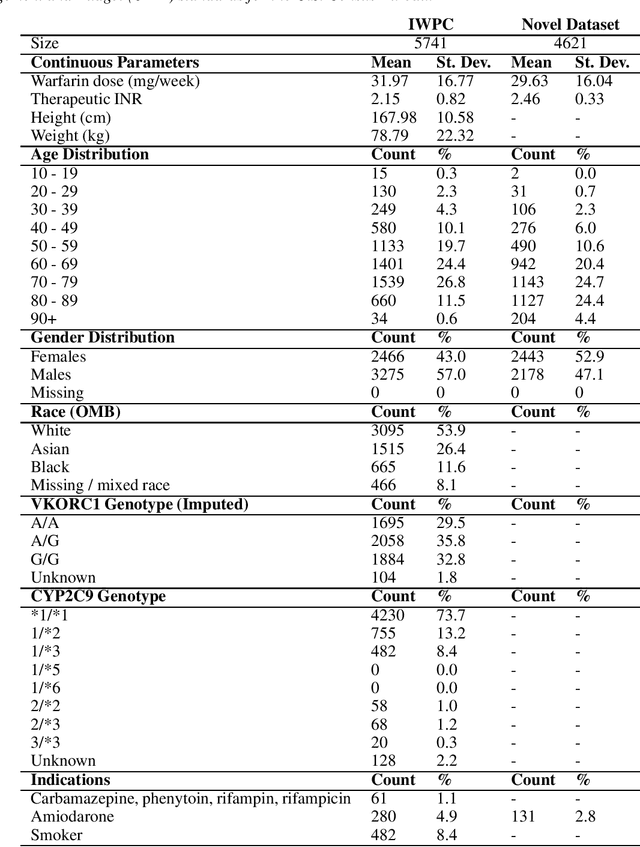

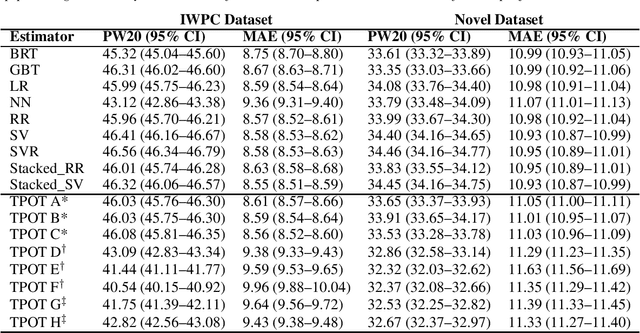
Warfarin is an effective preventative treatment for arterial and venous thromboembolism, but requires individualised dosing due to its narrow therapeutic range and high individual variation. A plethora of statistical and machine learning techniques have been demonstrated in this domain. This study evaluated the accuracy of the most promising algorithms on the International Warfarin Pharmacogenetics Consortium dataset and a novel clinical dataset of South African patients. Support vectors and linear regression were consistently amongst the top performers in both datasets and performed comparably to recent ensemble approaches. We also evaluated the use of genetic programming to design and optimise learning models without human guidance, finding that performance matched that of models hand-crafted by human experts. Finally, we present a novel software framework (warfit-learn) for standardising future research by leveraging the most successful techniques in preprocessing, imputation, and evaluation, with the goal of making results more reproducible in this domain.