 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantified Sleep: Machine learning techniques for observational n-of-1 studies
Paper and Code
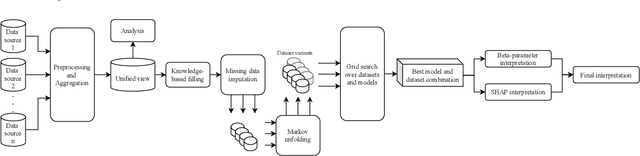
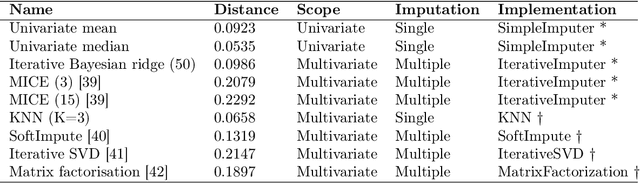
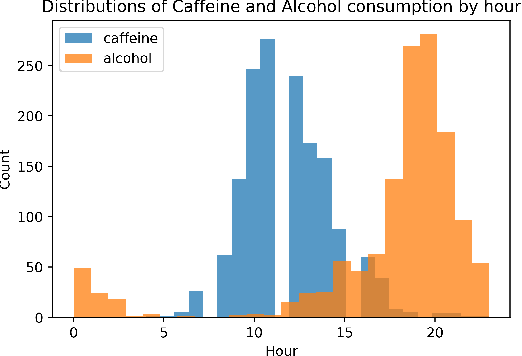
This paper applies statistical learning techniques to an observational Quantified-Self (QS) study to build a descriptive model of sleep quality. A total of 472 days of my sleep data was collected with an Oura ring and combined with lifestyle, environmental, and psychological data. Such n-of-1 QS projects pose a number of challenges: heterogeneous data sources; missing values; high dimensionality; dynamic feedback loops; human biases. This paper directly addresses these challenges with an end-to-end QS pipeline that produces robust descriptive models. Sleep quality is one of the most difficult modelling targets in QS research, due to high noise and a large number of weakly-contributing factors. Sleep quality was selected so that approaches from this paper would generalise to most other n-of-1 QS projects. Techniques are presented for combining and engineering features for the different classes of data types, sample frequencies, and schema - including event logs, weather, and geo-spatial data. Statistical analyses for outliers, normality, (auto)correlation, stationarity, and missing data are detailed, along with a proposed method for hierarchical clustering to identify correlated groups of features. The missing data was overcome using a combination of knowledge-based and statistical techniques, including several multivariate imputation algorithms. "Markov unfolding" is presented for collapsing the time series into a collection of independent observations, whilst incorporating historical information. The final model was interpreted in two ways: by inspecting the internal $\beta$-parameters, and using the SHAP framework. These two interpretation techniques were combined to produce a list of the 16 most-predictive features, demonstrating that an observational study can greatly narrow down the number of features that need to be considered when designing interventional QS studies.