 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlled Query Evaluation through Epistemic Dependencies
May 03, 2024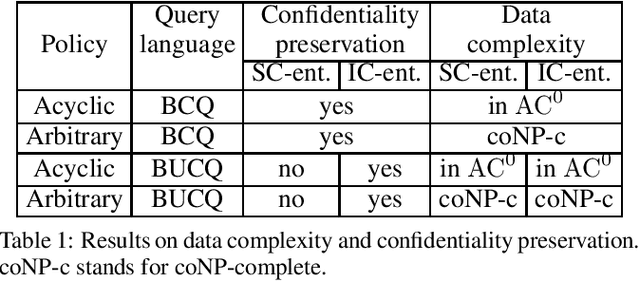
In this paper, we propose the use of epistemic dependencies to express data protection policies in Controlled Query Evaluation (CQE), which is a form of confidentiality-preserving query answering over ontologies and databases. The resulting policy language goes significantly beyond those proposed in the literature on CQE so far, allowing for very rich and practically interesting forms of data protection rules. We show the expressive abilities of our framework and study the data complexity of CQE for (unions of) conjunctive queries when ontologies are specified in the Description Logic DL-Lite_R. Interestingly, while we show that the problem is in general intractable, we prove tractability for the case of acyclic epistemic dependencies by providing a suitable query rewriting algorithm. The latter result paves the way towards the implementation and practical application of this new approach to CQE.
Combining Global and Local Merges in Logic-based Entity Resolution
May 29, 2023
In the recently proposed Lace framework for collective entity resolution, logical rules and constraints are used to identify pairs of entity references (e.g. author or paper ids) that denote the same entity. This identification is global: all occurrences of those entity references (possibly across multiple database tuples) are deemed equal and can be merged. By contrast, a local form of merge is often more natural when identifying pairs of data values, e.g. some occurrences of 'J. Smith' may be equated with 'Joe Smith', while others should merge with 'Jane Smith'. This motivates us to extend Lace with local merges of values and explore the computational properties of the resulting formalism.
CQE in OWL 2 QL: A "Longest Honeymoon" Approach
Jul 22, 2022Controlled Query Evaluation (CQE) has been recently studied in the context of Semantic Web ontologies. The goal of CQE is concealing some query answers so as to prevent external users from inferring confidential information. In general, there exist multiple, mutually incomparable ways of concealing answers, and previous CQE approaches choose in advance which answers are visible and which are not. In this paper, instead, we study a dynamic CQE method, namely, we propose to alter the answer to the current query based on the evaluation of previous ones. We aim at a system that, besides being able to protect confidential data, is maximally cooperative, which intuitively means that it answers affirmatively to as many queries as possible; it achieves this goal by delaying answer modifications as much as possible. We also show that the behavior we get cannot be intensionally simulated through a static approach, independent of query history. Interestingly, for OWL 2 QL ontologies and policy expressed through denials, query evaluation under our semantics is first-order rewritable, and thus in AC0 in data complexity. This paves the way for the development of practical algorithms, which we also preliminarily discuss in the paper.
QDEF and Its Approximations in OBDM
Aug 23, 2021Given an input dataset (i.e., a set of tuples), query definability in Ontology-based Data Management (OBDM) amounts to find a query over the ontology whose certain answers coincide with the tuples in the given dataset. We refer to such a query as a characterization of the dataset with respect to the OBDM system. Our first contribution is to propose approximations of perfect characterizations in terms of recall (complete characterizations) and precision (sound characterizations). A second contribution is to present a thorough complexity analysis of three computational problems, namely verification (check whether a given query is a perfect, or an approximated characterization of a given dataset), existence (check whether a perfect, or a best approximated characterization of a given dataset exists), and computation (compute a perfect, or best approximated characterization of a given dataset).
CQE in Description Logics Through Instance Indistinguishability (extended version)
Apr 24, 2020We study privacy-preserving query answering in Description Logics (DLs). Specifically, we consider the approach of controlled query evaluation (CQE) based on the notion of instance indistinguishability. We derive data complexity results for query answering over DL-Lite$_{\mathcal{R}}$ ontologies, through a comparison with an alternative, existing confidentiality-preserving approach to CQE. Finally, we identify a semantically well-founded notion of approximated query answering for CQE, and prove that, for DL-Lite$_{\mathcal{R}}$ ontologies, this form of CQE is tractable with respect to data complexity and is first-order rewritable, i.e., it is always reducible to the evaluation of a first-order query over the data instance.
Preliminary results on Ontology-based Open Data Publishing
Jul 13, 2017Despite the current interest in Open Data publishing, a formal and comprehensive methodology supporting an organization in deciding which data to publish and carrying out precise procedures for publishing high-quality data, is still missing. In this paper we argue that the Ontology-based Data Management paradigm can provide a formal basis for a principled approach to publish high quality, semantically annotated Open Data. We describe two main approaches to using an ontology for this endeavor, and then we present some technical results on one of the approaches, called bottom-up, where the specification of the data to be published is given in terms of the sources, and specific techniques allow deriving suitable annotations for interpreting the published data under the light of the ontology.