 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic large language models improve retrieval-based radiology question answering
Aug 01, 2025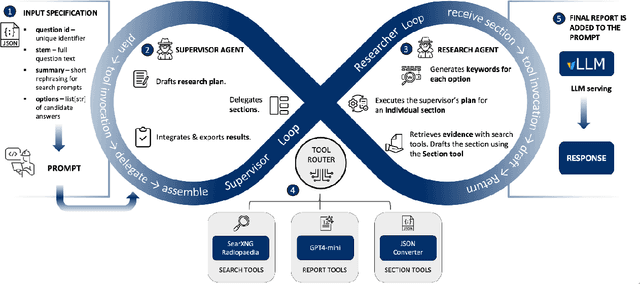
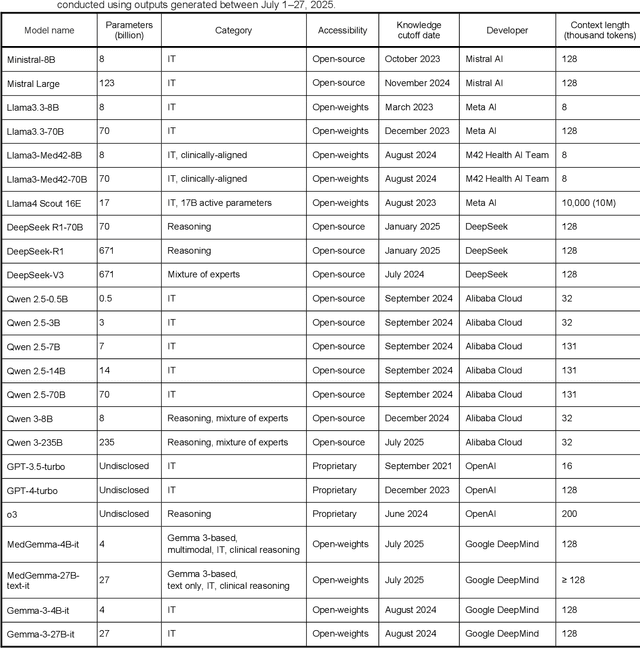
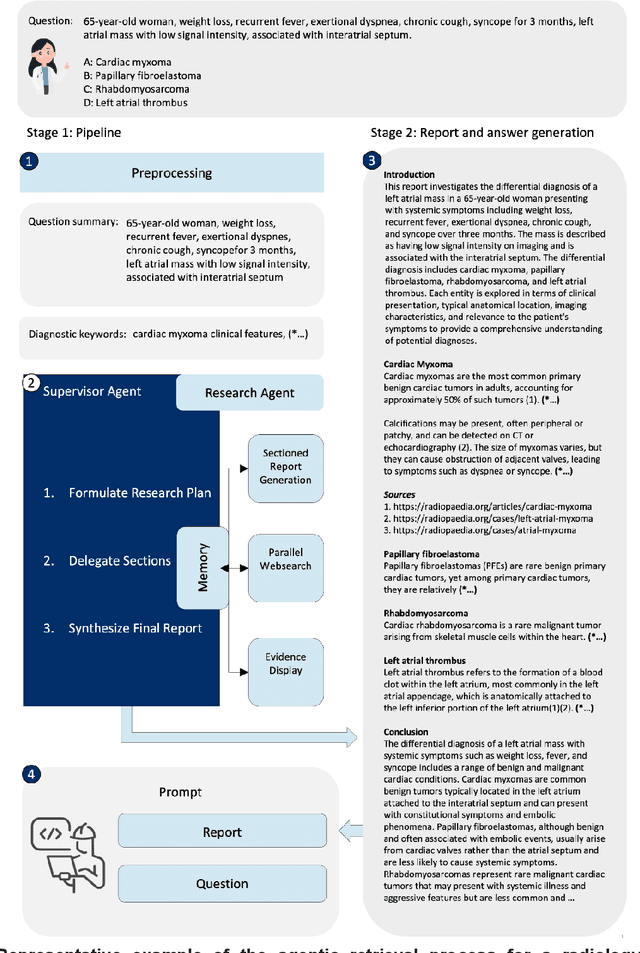
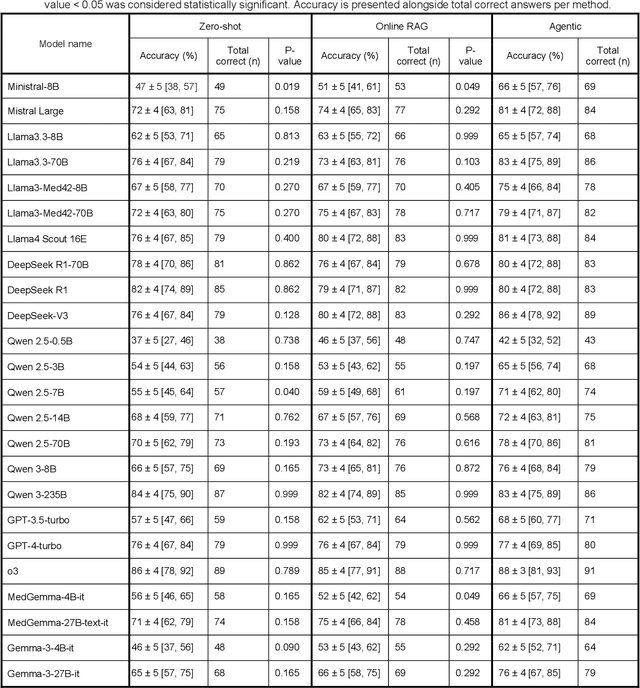
Clinical decision-making in radiology increasingly benefits from artificial intelligence (AI), particularly through large language models (LLMs). However, traditional retrieval-augmented generation (RAG) systems for radiology question answering (QA) typically rely on single-step retrieval, limiting their ability to handle complex clinical reasoning tasks. Here we propose an agentic RAG framework enabling LLMs to autonomously decompose radiology questions, iteratively retrieve targeted clinical evidence from Radiopaedia, and dynamically synthesize evidence-based responses. We evaluated 24 LLMs spanning diverse architectures, parameter scales (0.5B to >670B), and training paradigms (general-purpose, reasoning-optimized, clinically fine-tuned), using 104 expert-curated radiology questions from previously established RSNA-RadioQA and ExtendedQA datasets. Agentic retrieval significantly improved mean diagnostic accuracy over zero-shot prompting (73% vs. 64%; P<0.001) and conventional online RAG (73% vs. 68%; P<0.001). The greatest gains occurred in mid-sized models (e.g., Mistral Large improved from 72% to 81%) and small-scale models (e.g., Qwen 2.5-7B improved from 55% to 71%), while very large models (>200B parameters) demonstrated minimal changes (<2% improvement). Additionally, agentic retrieval reduced hallucinations (mean 9.4%) and retrieved clinically relevant context in 46% of cases, substantially aiding factual grounding. Even clinically fine-tuned models exhibited meaningful improvements (e.g., MedGemma-27B improved from 71% to 81%), indicating complementary roles of retrieval and fine-tuning. These results highlight the potential of agentic frameworks to enhance factuality and diagnostic accuracy in radiology QA, particularly among mid-sized LLMs, warranting future studies to validate their clinical utility.
Exploring Techniques for the Analysis of Spontaneous Asynchronicity in MPI-Parallel Applications
May 27, 2022
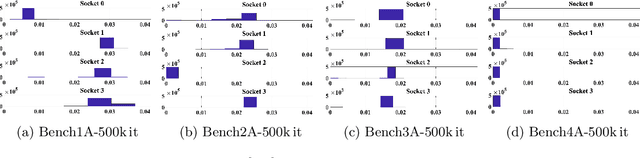
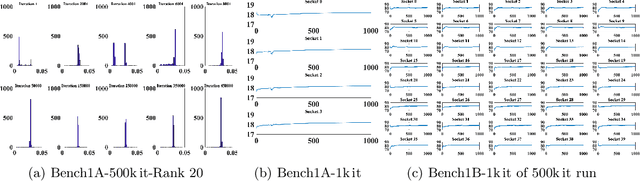
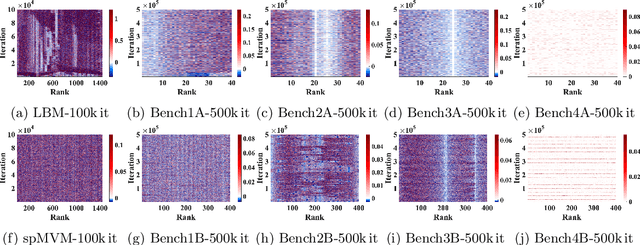
This paper studies the utility of using data analytics and machine learning techniques for identifying, classifying, and characterizing the dynamics of large-scale parallel (MPI) programs. To this end, we run microbenchmarks and realistic proxy applications with the regular compute-communicate structure on two different supercomputing platforms and choose the per-process performance and MPI time per time step as relevant observables. Using principal component analysis, clustering techniques, correlation functions, and a new "phase space plot," we show how desynchronization patterns (or lack thereof) can be readily identified from a data set that is much smaller than a full MPI trace. Our methods also lead the way towards a more general classification of parallel program dynamics.
$K$-way $p$-spectral clustering on Grassmann manifolds
Aug 30, 2020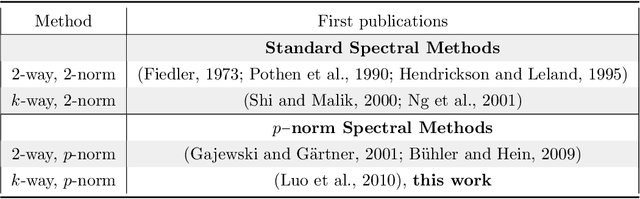
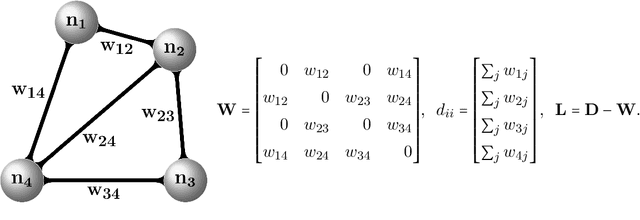
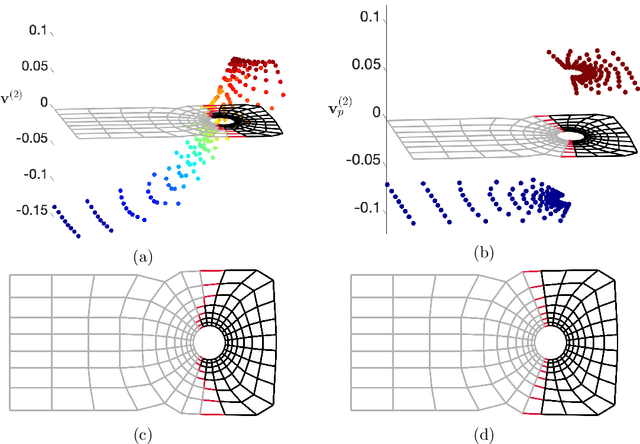
Spectral methods have gained a lot of recent attention due to the simplicity of their implementation and their solid mathematical background. We revisit spectral graph clustering, and reformulate in the $p$-norm the continuous problem of minimizing the graph Laplacian Rayleigh quotient. The value of $p \in (1,2]$ is reduced, promoting sparser solution vectors that correspond to optimal clusters as $p$ approaches one. The computation of multiple $p$-eigenvectors of the graph $p$-Laplacian, a nonlinear generalization of the standard graph Laplacian, is achieved by the minimization of our objective function on the Grassmann manifold, hence ensuring the enforcement of the orthogonality constraint between them. Our approach attempts to bridge the fields of graph clustering and nonlinear numerical optimization, and employs a robust algorithm to obtain clusters of high quality. The benefits of the suggested method are demonstrated in a plethora of artificial and real-world graphs. Our results are compared against standard spectral clustering methods and the current state-of-the-art algorithm for clustering using the graph $p$-Laplacian variant.
Performance Engineering for a Medical Imaging Application on the Intel Xeon Phi Accelerator
Dec 17, 2013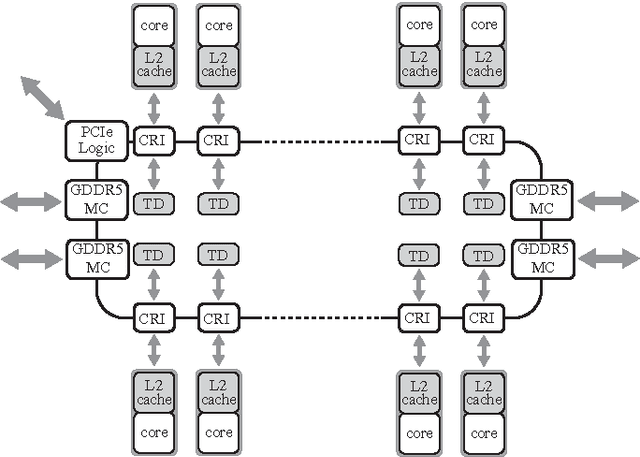

We examine the Xeon Phi, which is based on Intel's Many Integrated Cores architecture, for its suitability to run the FDK algorithm--the most commonly used algorithm to perform the 3D image reconstruction in cone-beam computed tomography. We study the challenges of efficiently parallelizing the application and means to enable sensible data sharing between threads despite the lack of a shared last level cache. Apart from parallelization, SIMD vectorization is critical for good performance on the Xeon Phi; we perform various micro-benchmarks to investigate the platform's new set of vector instructions and put a special emphasis on the newly introduced vector gather capability. We refine a previous performance model for the application and adapt it for the Xeon Phi to validate the performance of our optimized hand-written assembly implementation, as well as the performance of several different auto-vectorization approaches.