 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Engineering for a Medical Imaging Application on the Intel Xeon Phi Accelerator
Dec 17, 2013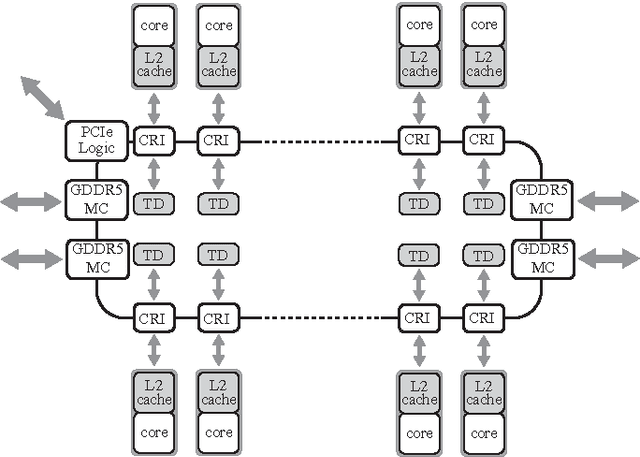
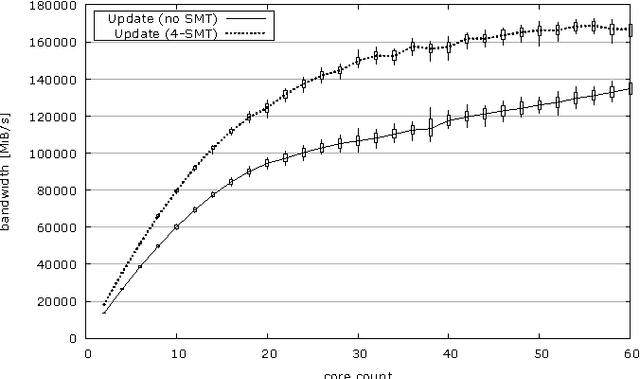

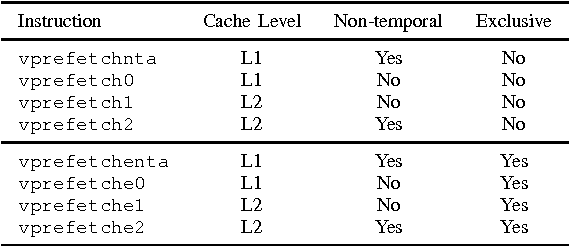
We examine the Xeon Phi, which is based on Intel's Many Integrated Cores architecture, for its suitability to run the FDK algorithm--the most commonly used algorithm to perform the 3D image reconstruction in cone-beam computed tomography. We study the challenges of efficiently parallelizing the application and means to enable sensible data sharing between threads despite the lack of a shared last level cache. Apart from parallelization, SIMD vectorization is critical for good performance on the Xeon Phi; we perform various micro-benchmarks to investigate the platform's new set of vector instructions and put a special emphasis on the newly introduced vector gather capability. We refine a previous performance model for the application and adapt it for the Xeon Phi to validate the performance of our optimized hand-written assembly implementation, as well as the performance of several different auto-vectorization approaches.