 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Art of Misclassification: Too Many Classes, Not Enough Points
Feb 12, 2025
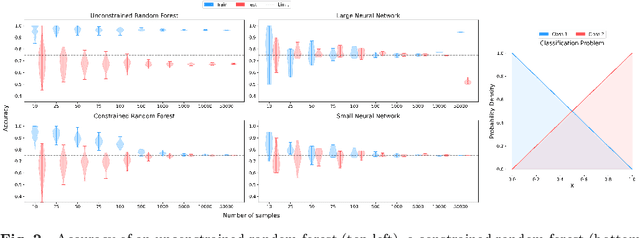
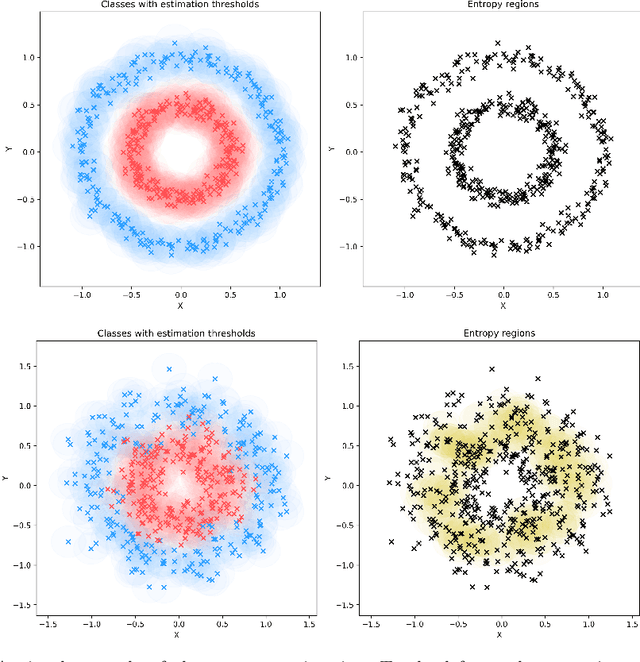
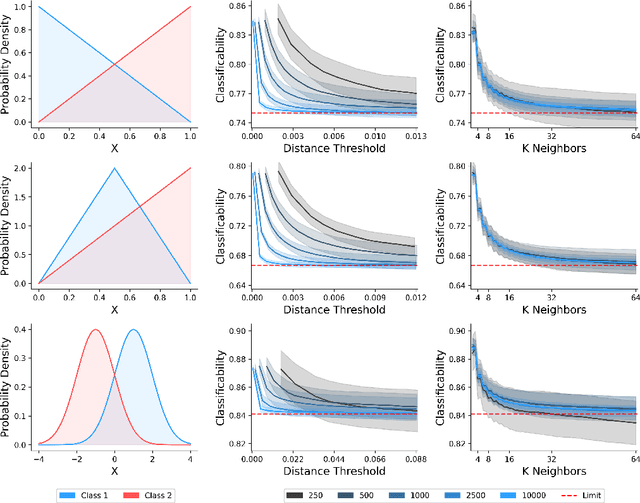
Classification is a ubiquitous and fundamental problem in artificial intelligence and machine learning, with extensive efforts dedicated to developing more powerful classifiers and larger datasets. However, the classification task is ultimately constrained by the intrinsic properties of datasets, independently of computational power or model complexity. In this work, we introduce a formal entropy-based measure of classificability, which quantifies the inherent difficulty of a classification problem by assessing the uncertainty in class assignments given feature representations. This measure captures the degree of class overlap and aligns with human intuition, serving as an upper bound on classification performance for classification problems. Our results establish a theoretical limit beyond which no classifier can improve the classification accuracy, regardless of the architecture or amount of data, in a given problem. Our approach provides a principled framework for understanding when classification is inherently fallible and fundamentally ambiguous.
Quantifying literature quality using complexity criteria
Jan 15, 2017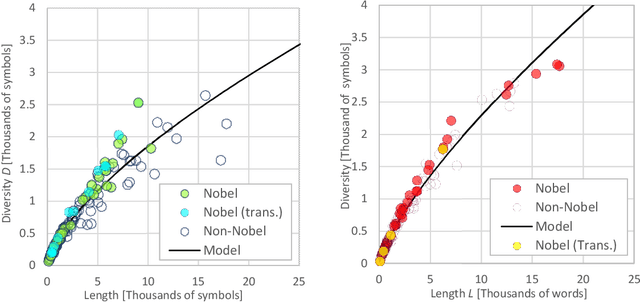
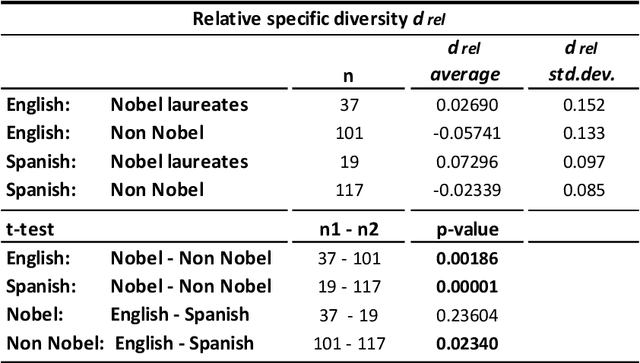
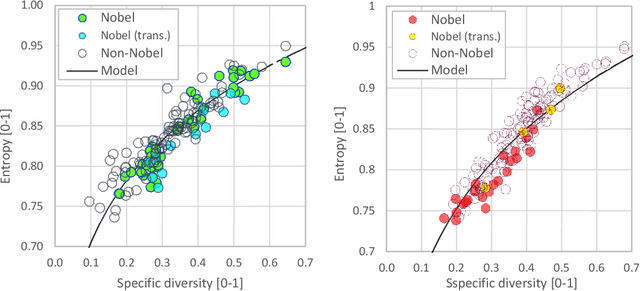
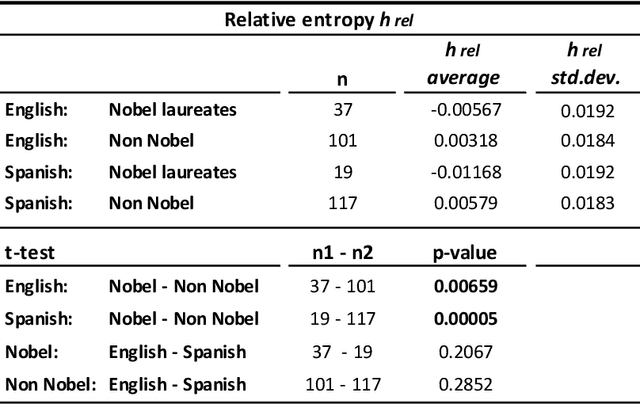
We measured entropy and symbolic diversity for English and Spanish texts including literature Nobel laureates and other famous authors. Entropy, symbol diversity and symbol frequency profiles were compared for these four groups. We also built a scale sensitive to the quality of writing and evaluated its relationship with the Flesch's readability index for English and the Szigriszt's perspicuity index for Spanish. Results suggest a correlation between entropy and word diversity with quality of writing. Text genre also influences the resulting entropy and diversity of the text. Results suggest the plausibility of automated quality assessment of texts.
* Submitted for publication. 29 pages. 8 figures, 4 tables, 4 appendixes
Calculating entropy at different scales among diverse communication systems
Oct 05, 2015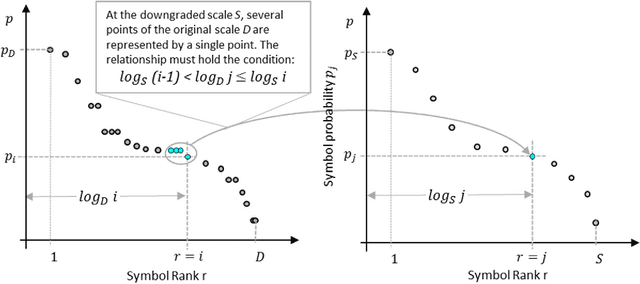
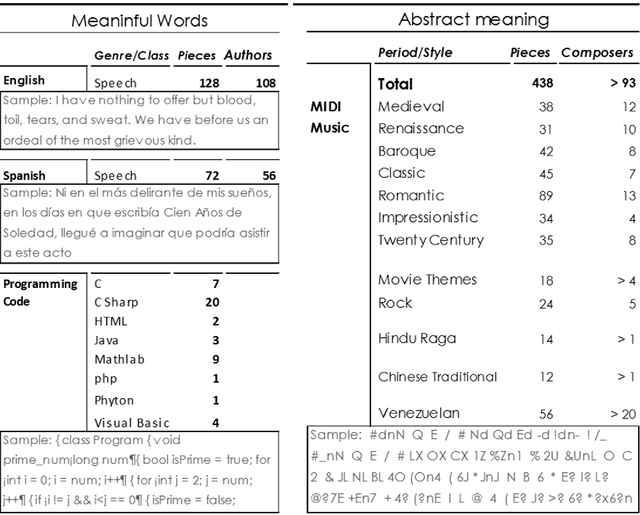
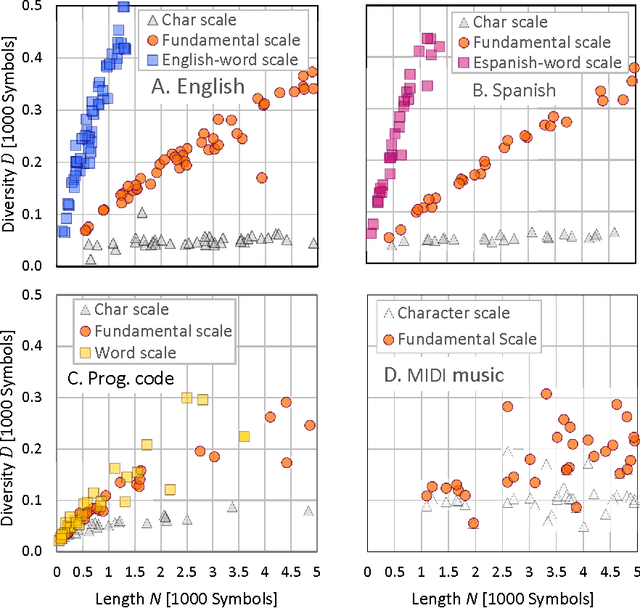
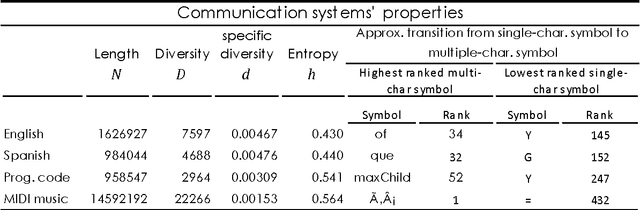
We evaluated the impact of changing the observation scale over the entropy measures for text descriptions. MIDI coded Music, computer code and two human natural languages were studied at the scale of characters, words, and at the Fundamental Scale resulting from adjusting the symbols length used to interpret each text-description until it produced minimum entropy. The results show that the Fundamental Scale method is comparable with the use of words when measuring entropy levels in written texts. However, this method can also be used in communication systems lacking words such as music. Measuring symbolic entropy at the fundamental scale allows to calculate quantitatively, relative levels of complexity for different communication systems. The results open novel vision on differences among the structure of the communication systems studied.
* 27 pages, 6 Figures, 6 Tables
Complexity measurement of natural and artificial languages
Nov 22, 2013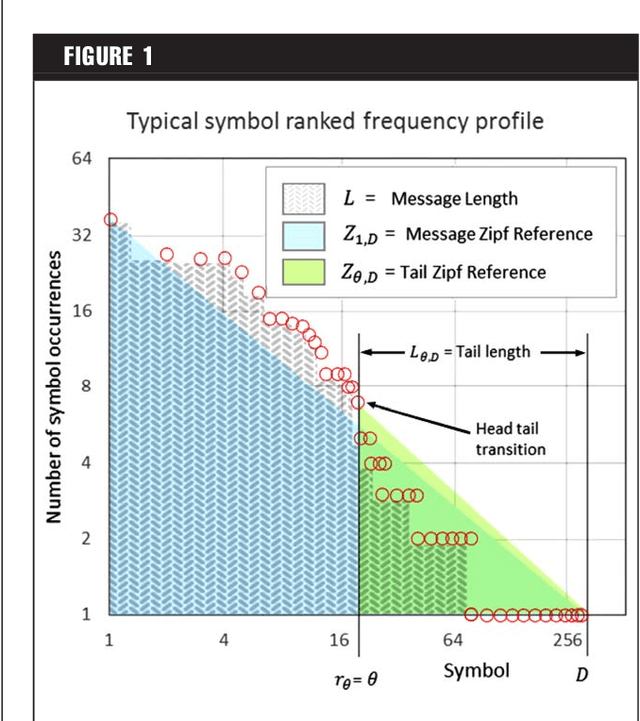
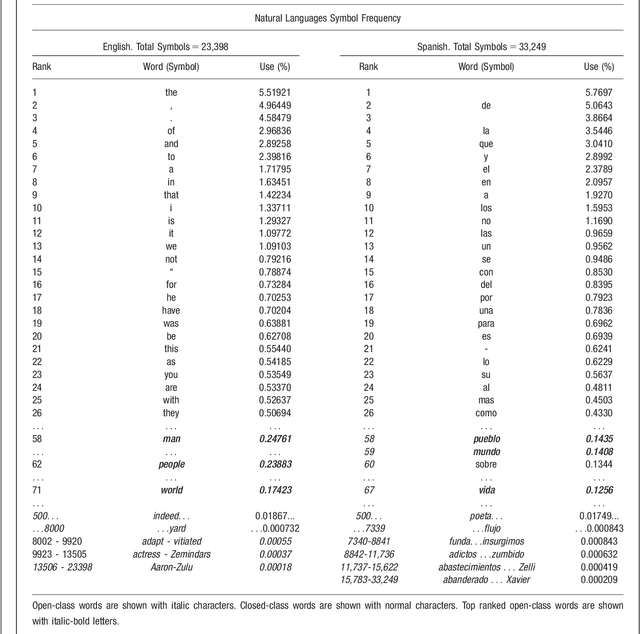
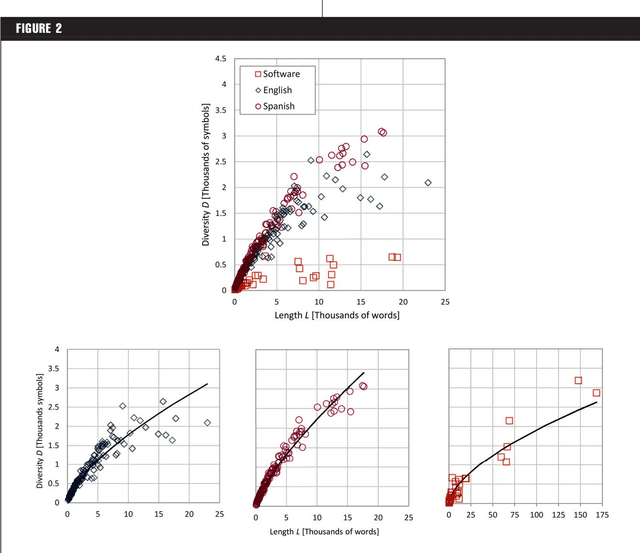
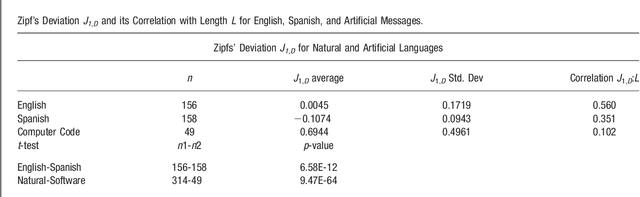
We compared entropy for texts written in natural languages (English, Spanish) and artificial languages (computer software) based on a simple expression for the entropy as a function of message length and specific word diversity. Code text written in artificial languages showed higher entropy than text of similar length expressed in natural languages. Spanish texts exhibit more symbolic diversity than English ones. Results showed that algorithms based on complexity measures differentiate artificial from natural languages, and that text analysis based on complexity measures allows the unveiling of important aspects of their nature. We propose specific expressions to examine entropy related aspects of tests and estimate the values of entropy, emergence, self-organization and complexity based on specific diversity and message length.
* 29 pages, 11 figures, 3 tables, 2 appendixes