 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Art of Misclassification: Too Many Classes, Not Enough Points
Paper and Code

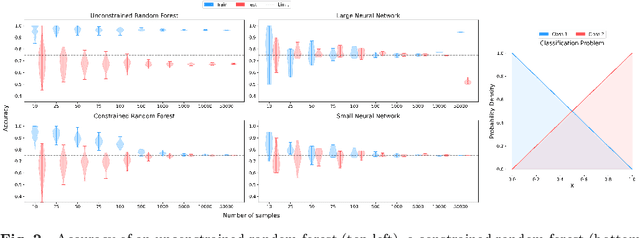
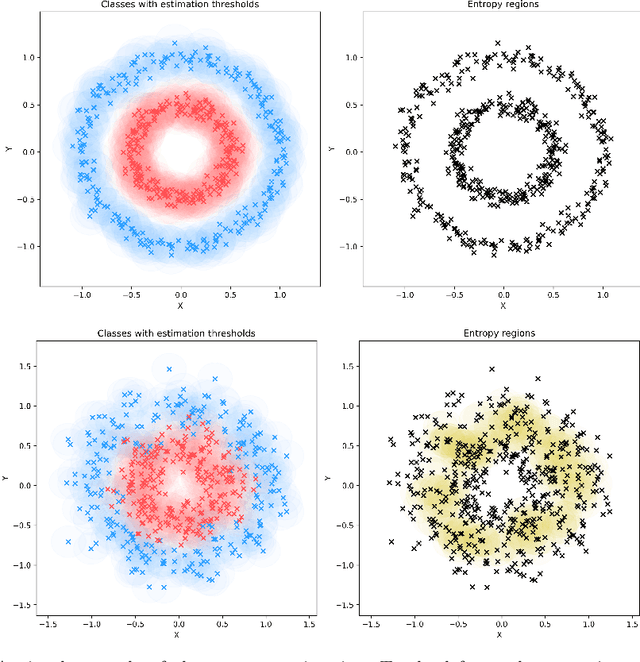
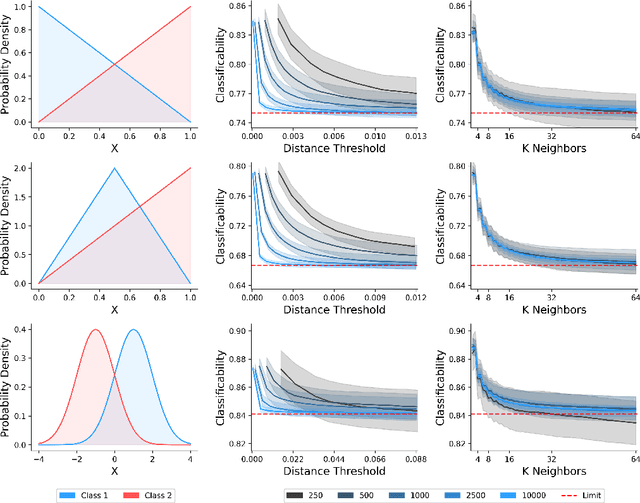
Classification is a ubiquitous and fundamental problem in artificial intelligence and machine learning, with extensive efforts dedicated to developing more powerful classifiers and larger datasets. However, the classification task is ultimately constrained by the intrinsic properties of datasets, independently of computational power or model complexity. In this work, we introduce a formal entropy-based measure of classificability, which quantifies the inherent difficulty of a classification problem by assessing the uncertainty in class assignments given feature representations. This measure captures the degree of class overlap and aligns with human intuition, serving as an upper bound on classification performance for classification problems. Our results establish a theoretical limit beyond which no classifier can improve the classification accuracy, regardless of the architecture or amount of data, in a given problem. Our approach provides a principled framework for understanding when classification is inherently fallible and fundamentally ambiguous.