 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch Inspired Exploration in Reinforcement Learning
Jan 31, 2026Exploration in environments with sparse rewards remains a fundamental challenge in reinforcement learning (RL). Existing approaches such as curriculum learning and Go-Explore often rely on hand-crafted heuristics, while curiosity-driven methods risk converging to suboptimal policies. We propose Search-Inspired Exploration in Reinforcement Learning (SIERL), a novel method that actively guides exploration by setting sub-goals based on the agent's learning progress. At the beginning of each episode, SIERL chooses a sub-goal from the \textit{frontier} (the boundary of the agent's known state space), before the agent continues exploring toward the main task objective. The key contribution of our method is the sub-goal selection mechanism, which provides state-action pairs that are neither overly familiar nor completely novel. Thus, it assures that the frontier is expanded systematically and that the agent is capable of reaching any state within it. Inspired by search, sub-goals are prioritized from the frontier based on estimates of cost-to-come and cost-to-go, effectively steering exploration towards the most informative regions. In experiments on challenging sparse-reward environments, SIERL outperforms dominant baselines in both achieving the main task goal and generalizing to reach arbitrary states in the environment.
Search-based versus Sampling-based Robot Motion Planning: A Comparative Study
Jun 17, 2024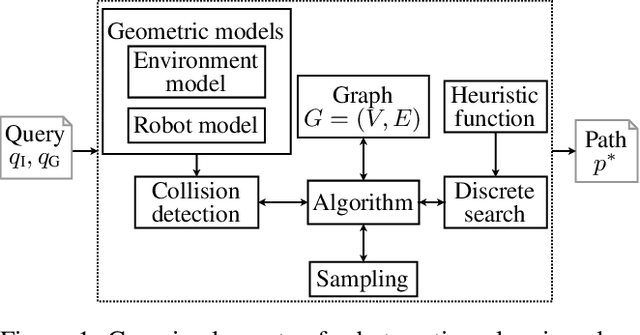


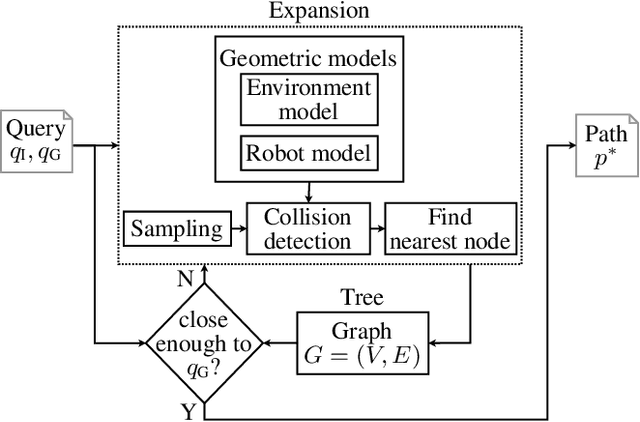
Robot motion planning is a challenging domain as it involves dealing with high-dimensional and continuous search space. In past decades, a wide variety of planning algorithms have been developed to tackle this problem, sometimes in isolation without comparing to each other. In this study, we benchmark two such prominent types of algorithms: OMPL's sampling-based RRT-Connect and SMPL's search-based ARA* with motion primitives. To compare these two fundamentally different approaches fairly, we adapt them to ensure the same planning conditions and benchmark them on the same set of planning scenarios. Our findings suggest that sampling-based planners like RRT-Connect show more consistent performance across the board in high-dimensional spaces, whereas search-based planners like ARA* have the capacity to perform significantly better when used with a suitable action-space sampling scheme. Through this study, we hope to showcase the effort required to properly benchmark motion planners from different paradigms thereby contributing to a more nuanced understanding of their capabilities and limitations. The code is available at https://github.com/gsotirchos/benchmarking_planners