 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Adversarial Collaboration for Advancing Theory Building in the Cognitive Sciences
Apr 28, 2026Cognitive science often evaluates theories through narrow paradigms and local model comparisons, limiting the integration of evidence across tasks and realizations. We introduce an automated adversarial collaboration framework for adjudicating among competing theories even when the candidate models and experiments must be discovered during the adjudication process. The system combines LLM-based theory agents, program synthesis, and information-theoretic experimental design in a closed loop. In a simulation study spanning three classic categorization theories, the framework recovered the ground-truth theory across noise settings with weaker reliability in the hardest settings. Together, the framework and findings provide a concrete proof of concept for closed-loop, in-silico theory adjudication in cognitive science.
Computational and Robotic Models of Early Language Development: A Review
Mar 25, 2019
We review computational and robotics models of early language learning and development. We first explain why and how these models are used to understand better how children learn language. We argue that they provide concrete theories of language learning as a complex dynamic system, complementing traditional methods in psychology and linguistics. We review different modeling formalisms, grounded in techniques from machine learning and artificial intelligence such as Bayesian and neural network approaches. We then discuss their role in understanding several key mechanisms of language development: cross-situational statistical learning, embodiment, situated social interaction, intrinsically motivated learning, and cultural evolution. We conclude by discussing future challenges for research, including modeling of large-scale empirical data about language acquisition in real-world environments. Keywords: Early language learning, Computational and robotic models, machine learning, development, embodiment, social interaction, intrinsic motivation, self-organization, dynamical systems, complexity.
The Mafiascum Dataset: A Large Text Corpus for Deception Detection
Nov 19, 2018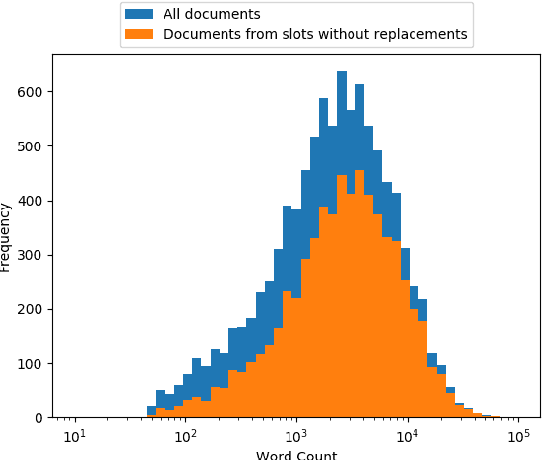
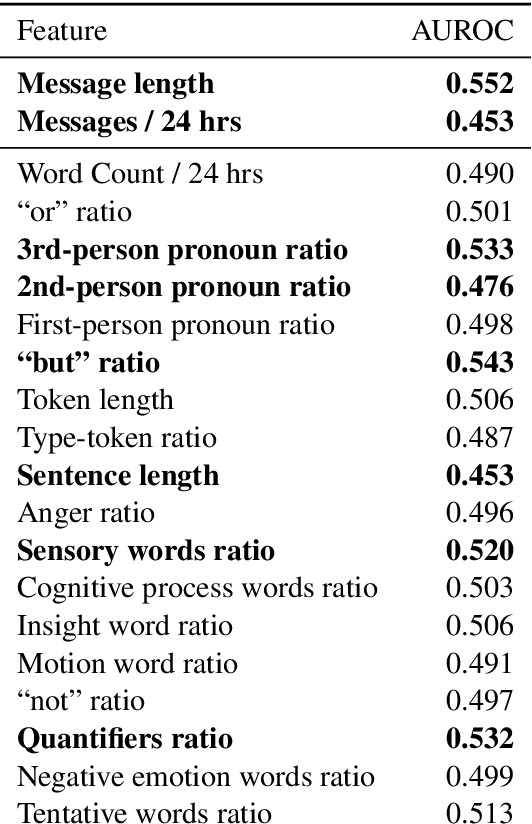
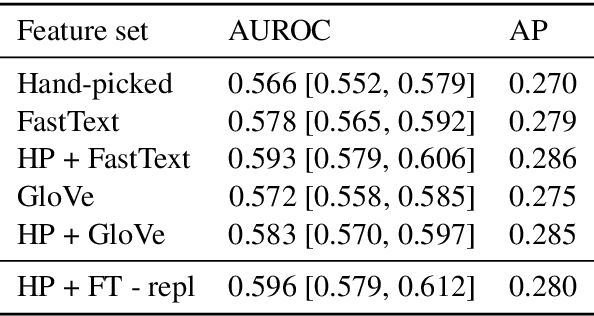
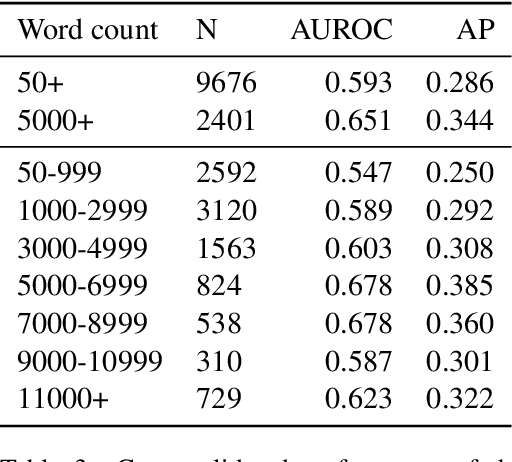
Detecting deception in natural language has a wide variety of applications, but because of its hidden nature there are no public, large-scale sources of labeled deceptive text. This work introduces the Mafiascum dataset [1], a collection of over 700 games of Mafia, in which players are randomly assigned either deceptive or non-deceptive roles and then interact via forum postings. Almost 10,000 documents were compiled from the dataset, which each contained all messages written by a single player in a single game. This corpus was used to construct a set of hand-picked linguistic features based on prior deception research and a set of average word vectors enriched with subword information. An SVM classifier fit on a combination of these feature sets achieved an area under the precision-recall curve of 0.35 (chance = 0.26) and an ROC AUC of 0.64 (chance = 0.50). [1] https://bitbucket.org/bopjesvla/thesis/src