 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Dynamic Correlation Shifts and Weighted Benchmarking in Extreme Value Analysis
Nov 19, 2024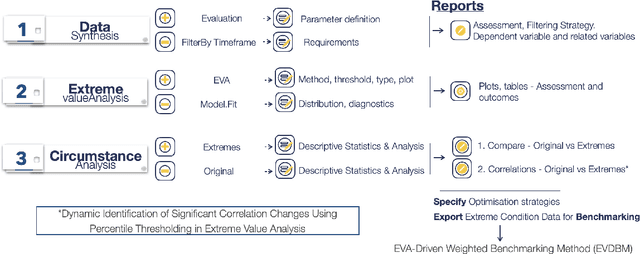
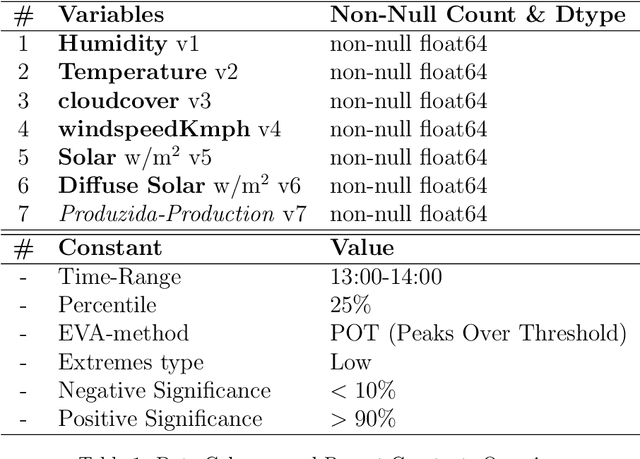
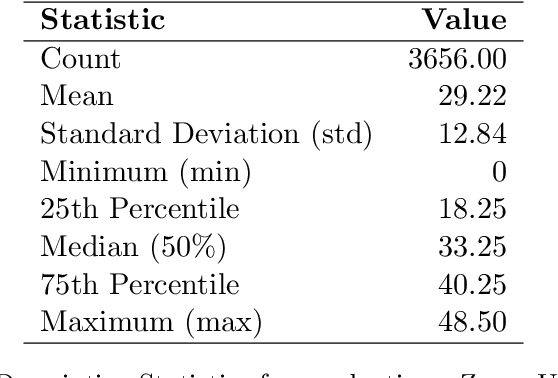
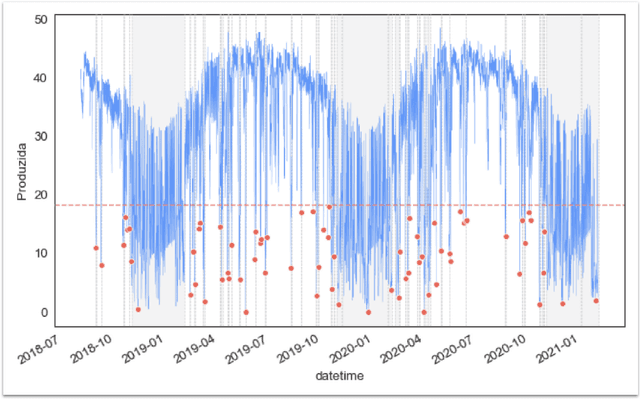
This paper presents an innovative approach to Extreme Value Analysis (EVA) by introducing the Extreme Value Dynamic Benchmarking Method (EVDBM). EVDBM integrates extreme value theory to detect extreme events and is coupled with the novel Dynamic Identification of Significant Correlation (DISC)-Thresholding algorithm, which enhances the analysis of key variables under extreme conditions. By integrating return values predicted through EVA into the benchmarking scores, we are able to transform these scores to reflect anticipated conditions more accurately. This provides a more precise picture of how each case is projected to unfold under extreme conditions. As a result, the adjusted scores offer a forward-looking perspective, highlighting potential vulnerabilities and resilience factors for each case in a way that static historical data alone cannot capture. By incorporating both historical and probabilistic elements, the EVDBM algorithm provides a comprehensive benchmarking framework that is adaptable to a range of scenarios and contexts. The methodology is applied to real PV data, revealing critical low - production scenarios and significant correlations between variables, which aid in risk management, infrastructure design, and long-term planning, while also allowing for the comparison of different production plants. The flexibility of EVDBM suggests its potential for broader applications in other sectors where decision-making sensitivity is crucial, offering valuable insights to improve outcomes.
COGNET-MD, an evaluation framework and dataset for Large Language Model benchmarks in the medical domain
May 17, 2024
Large Language Models (LLMs) constitute a breakthrough state-of-the-art Artificial Intelligence (AI) technology which is rapidly evolving and promises to aid in medical diagnosis either by assisting doctors or by simulating a doctor's workflow in more advanced and complex implementations. In this technical paper, we outline Cognitive Network Evaluation Toolkit for Medical Domains (COGNET-MD), which constitutes a novel benchmark for LLM evaluation in the medical domain. Specifically, we propose a scoring-framework with increased difficulty to assess the ability of LLMs in interpreting medical text. The proposed framework is accompanied with a database of Multiple Choice Quizzes (MCQs). To ensure alignment with current medical trends and enhance safety, usefulness, and applicability, these MCQs have been constructed in collaboration with several associated medical experts in various medical domains and are characterized by varying degrees of difficulty. The current (first) version of the database includes the medical domains of Psychiatry, Dentistry, Pulmonology, Dermatology and Endocrinology, but it will be continuously extended and expanded to include additional medical domains.
Dermacen Analytica: A Novel Methodology Integrating Multi-Modal Large Language Models with Machine Learning in tele-dermatology
Mar 21, 2024



The rise of Artificial Intelligence creates great promise in the field of medical discovery, diagnostics and patient management. However, the vast complexity of all medical domains require a more complex approach that combines machine learning algorithms, classifiers, segmentation algorithms and, lately, large language models. In this paper, we describe, implement and assess an Artificial Intelligence-empowered system and methodology aimed at assisting the diagnosis process of skin lesions and other skin conditions within the field of dermatology that aims to holistically address the diagnostic process in this domain. The workflow integrates large language, transformer-based vision models and sophisticated machine learning tools. This holistic approach achieves a nuanced interpretation of dermatological conditions that simulates and facilitates a dermatologist's workflow. We assess our proposed methodology through a thorough cross-model validation technique embedded in an evaluation pipeline that utilizes publicly available medical case studies of skin conditions and relevant images. To quantitatively score the system performance, advanced machine learning and natural language processing tools are employed which focus on similarity comparison and natural language inference. Additionally, we incorporate a human expert evaluation process based on a structured checklist to further validate our results. We implemented the proposed methodology in a system which achieved approximate (weighted) scores of 0.87 for both contextual understanding and diagnostic accuracy, demonstrating the efficacy of our approach in enhancing dermatological analysis. The proposed methodology is expected to prove useful in the development of next-generation tele-dermatology applications, enhancing remote consultation capabilities and access to care, especially in underserved areas.
Evaluating LLM -- Generated Multimodal Diagnosis from Medical Images and Symptom Analysis
Jan 28, 2024Large language models (LLMs) constitute a breakthrough state-of-the-art Artificial Intelligence technology which is rapidly evolving and promises to aid in medical diagnosis. However, the correctness and the accuracy of their returns has not yet been properly evaluated. In this work, we propose an LLM evaluation paradigm that incorporates two independent steps of a novel methodology, namely (1) multimodal LLM evaluation via structured interactions and (2) follow-up, domain-specific analysis based on data extracted via the previous interactions. Using this paradigm, (1) we evaluate the correctness and accuracy of LLM-generated medical diagnosis with publicly available multimodal multiple-choice questions(MCQs) in the domain of Pathology and (2) proceed to a systemic and comprehensive analysis of extracted results. We used GPT-4-Vision-Preview as the LLM to respond to complex, medical questions consisting of both images and text, and we explored a wide range of diseases, conditions, chemical compounds, and related entity types that are included in the vast knowledge domain of Pathology. GPT-4-Vision-Preview performed quite well, scoring approximately 84\% of correct diagnoses. Next, we further analyzed the findings of our work, following an analytical approach which included Image Metadata Analysis, Named Entity Recognition and Knowledge Graphs. Weaknesses of GPT-4-Vision-Preview were revealed on specific knowledge paths, leading to a further understanding of its shortcomings in specific areas. Our methodology and findings are not limited to the use of GPT-4-Vision-Preview, but a similar approach can be followed to evaluate the usefulness and accuracy of other LLMs and, thus, improve their use with further optimization.