 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Combinatorial Ensembles for Defending Against Adversarial Examples
Sep 08, 2018

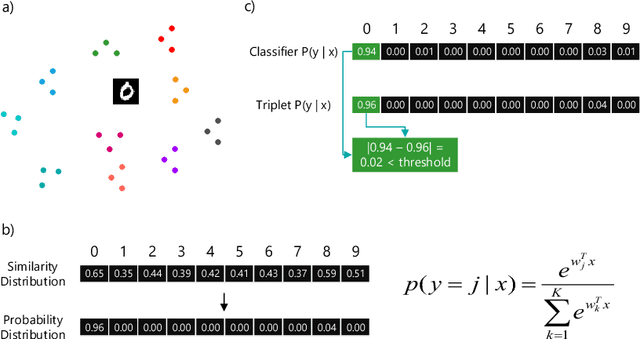
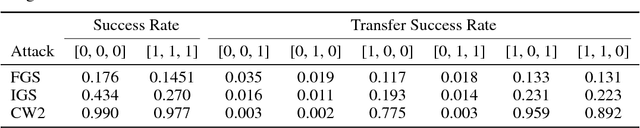
Many deep learning algorithms can be easily fooled with simple adversarial examples. To address the limitations of existing defenses, we devised a probabilistic framework that can generate an exponentially large ensemble of models from a single model with just a linear cost. This framework takes advantage of neural network depth and stochastically decides whether or not to insert noise removal operators such as VAEs between layers. We show empirically the important role that model gradients have when it comes to determining transferability of adversarial examples, and take advantage of this result to demonstrate that it is possible to train models with limited adversarial attack transferability. Additionally, we propose a detection method based on metric learning in order to detect adversarial examples that have no hope of being cleaned of maliciously engineered noise.