 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealthE: Classifying Entities in Online Textual Health Advice
Oct 06, 2022
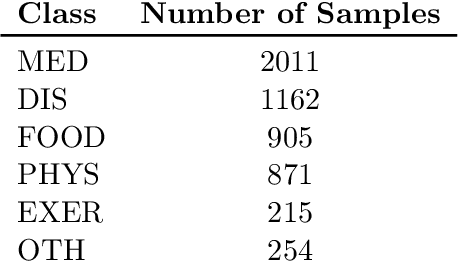


The processing of entities in natural language is essential to many medical NLP systems. Unfortunately, existing datasets vastly under-represent the entities required to model public health relevant texts such as health advice often found on sites like WebMD. People rely on such information for personal health management and clinically relevant decision making. In this work, we release a new annotated dataset, HealthE, consisting of 6,756 health advice. HealthE has a more granular label space compared to existing medical NER corpora and contains annotation for diverse health phrases. Additionally, we introduce a new health entity classification model, EP S-BERT, which leverages textual context patterns in the classification of entity classes. EP S-BERT provides a 4-point increase in F1 score over the nearest baseline and a 34-point increase in F1 when compared to off-the-shelf medical NER tools trained to extract disease and medication mentions from clinical texts. All code and data are publicly available on Github.