 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Approximation and Complexity of Deep Neural Networks to Invariant Functions
Oct 27, 2022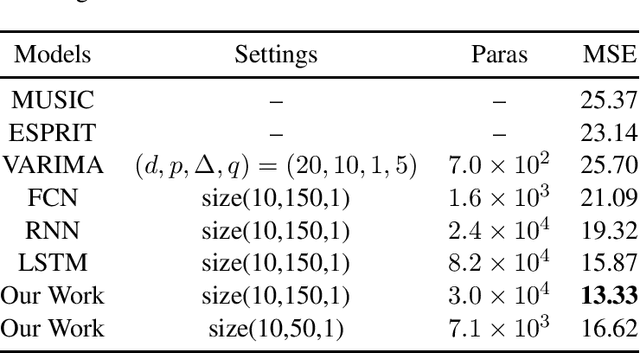
Recent years have witnessed a hot wave of deep neural networks in various domains; however, it is not yet well understood theoretically. A theoretical characterization of deep neural networks should point out their approximation ability and complexity, i.e., showing which architecture and size are sufficient to handle the concerned tasks. This work takes one step on this direction by theoretically studying the approximation and complexity of deep neural networks to invariant functions. We first prove that the invariant functions can be universally approximated by deep neural networks. Then we show that a broad range of invariant functions can be asymptotically approximated by various types of neural network models that includes the complex-valued neural networks, convolutional neural networks, and Bayesian neural networks using a polynomial number of parameters or optimization iterations. We also provide a feasible application that connects the parameter estimation and forecasting of high-resolution signals with our theoretical conclusions. The empirical results obtained on simulation experiments demonstrate the effectiveness of our method.