Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradual Learning of Recurrent Neural Networks
May 21, 2018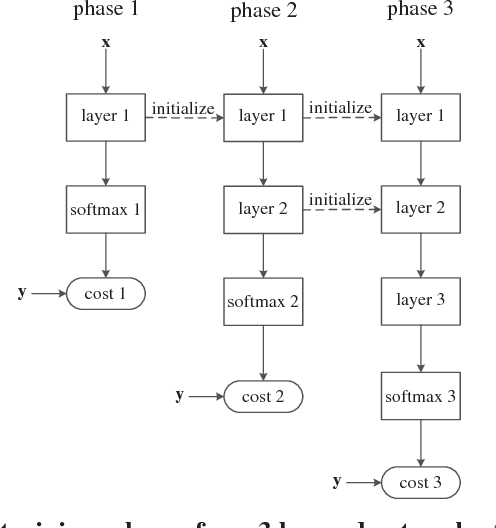
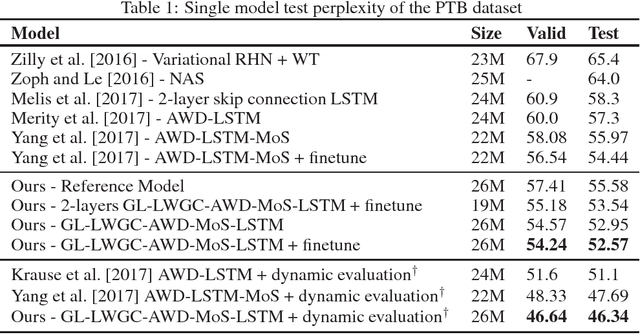
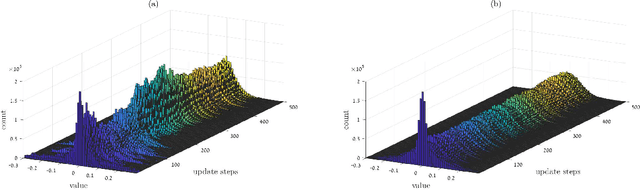

Recurrent Neural Networks (RNNs) achieve state-of-the-art results in many sequence-to-sequence modeling tasks. However, RNNs are difficult to train and tend to suffer from overfitting. Motivated by the Data Processing Inequality (DPI), we formulate the multi-layered network as a Markov chain, introducing a training method that comprises training the network gradually and using layer-wise gradient clipping. We found that applying our methods, combined with previously introduced regularization and optimization methods, resulted in improvements in state-of-the-art architectures operating in language modeling tasks.
* 8 pages, 2 figures
Via