 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISK: Dynamic Inference SKipping for World Models
Jan 31, 2026We present DISK, a training-free adaptive inference method for autoregressive world models. DISK coordinates two coupled diffusion transformers for video and ego-trajectory via dual-branch controllers with cross-modal skip decisions, preserving motion-appearance consistency without retraining. We extend higher-order latent-difference skip testing to the autoregressive chain-of-forward regime and propagate controller statistics through rollout loops for long-horizon stability. When integrated into closed-loop driving rollouts on 1500 NuPlan and NuScenes samples using an NVIDIA L40S GPU, DISK achieves 2x speedup on trajectory diffusion and 1.6x speedup on video diffusion while maintaining L2 planning error, visual quality (FID/FVD), and NAVSIM PDMS scores, demonstrating practical long-horizon video-and-trajectory prediction at substantially reduced cost.
FAST: Fast Audio Spectrogram Transformer
Jan 02, 2025


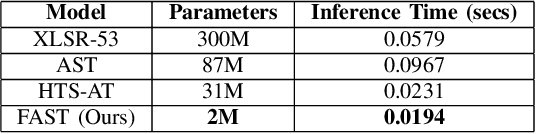
In audio classification, developing efficient and robust models is critical for real-time applications. Inspired by the design principles of MobileViT, we present FAST (Fast Audio Spectrogram Transformer), a new architecture that combines convolutional neural networks (CNNs) and transformers to capitalize on the strengths of both. FAST integrates the local feature extraction efficiencies of CNNs with the global context modeling capabilities of transformers, resulting in a model that is powerful yet lightweight, well-suited to a real-time or mobile use case. Additionally, we incorporate Lipschitz continuous attention mechanisms to improve training stability and accelerate convergence. We evaluate FAST on the ADIMA dataset, a multilingual corpus towards real-time profanity and abuse detection, as well as on the more traditional AudioSet. Our results show that FAST achieves state-of-the-art performance on both the ADIMA and AudioSet classification tasks and in some cases surpasses existing benchmarks while using up to 150x fewer parameters.