 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Learning Using Physicians Diagnostics for Optical Coherence Tomography Classification
Mar 20, 2022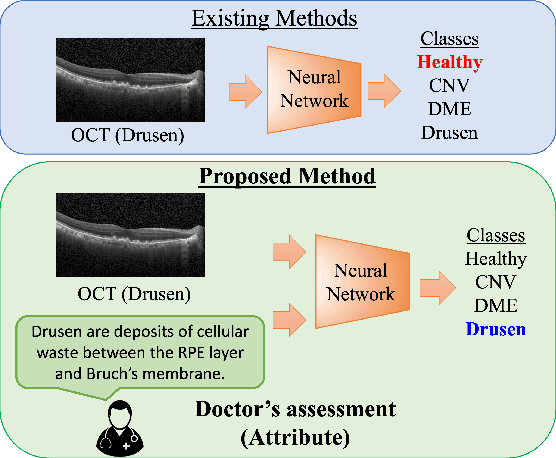
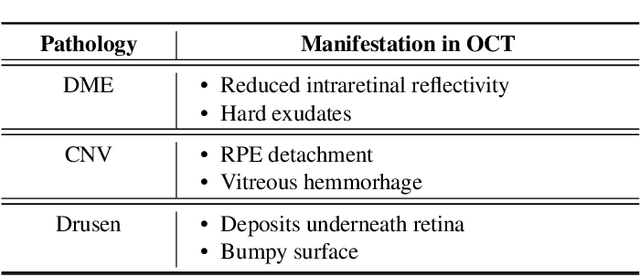
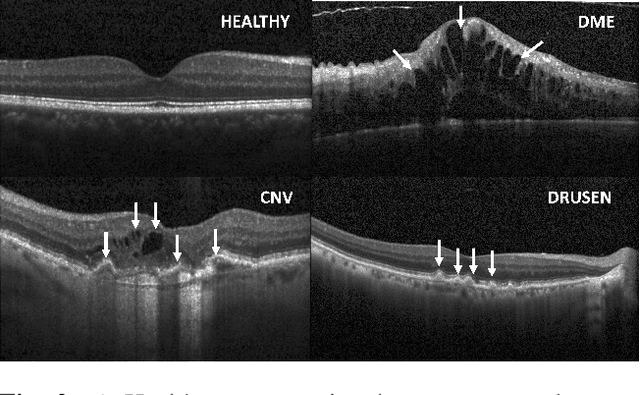
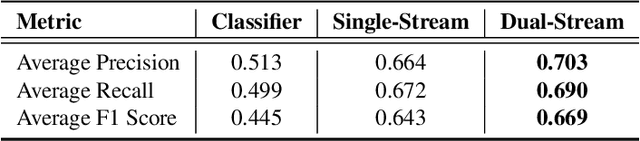
In this paper, we propose a framework that incorporates experts diagnostics and insights into the analysis of Optical Coherence Tomography (OCT) using multi-modal learning. To demonstrate the effectiveness of this approach, we create a medical diagnostic attribute dataset to improve disease classification using OCT. Although there have been successful attempts to deploy machine learning for disease classification in OCT, such methodologies lack the experts insights. We argue that injecting ophthalmological assessments as another supervision in a learning framework is of great importance for the machine learning process to perform accurate and interpretable classification. We demonstrate the proposed framework through comprehensive experiments that compare the effectiveness of combining diagnostic attribute features with latent visual representations and show that they surpass the state-of-the-art approach. Finally, we analyze the proposed dual-stream architecture and provide an insight that determine the components that contribute most to classification performance.
Subsurface structure analysis using computational interpretation and learning: A visual signal processing perspective
Dec 20, 2018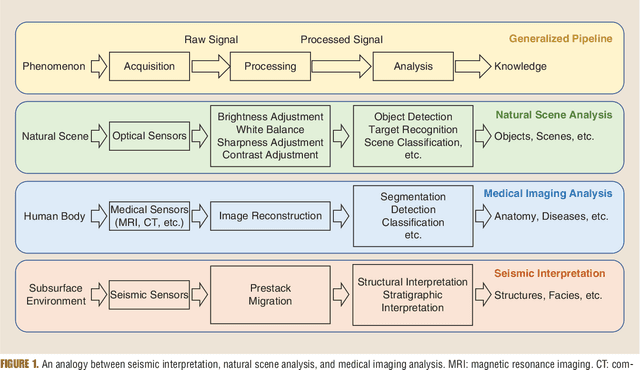
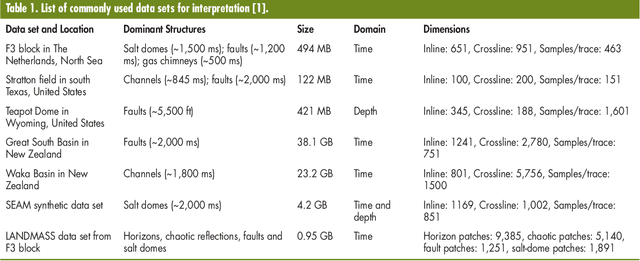

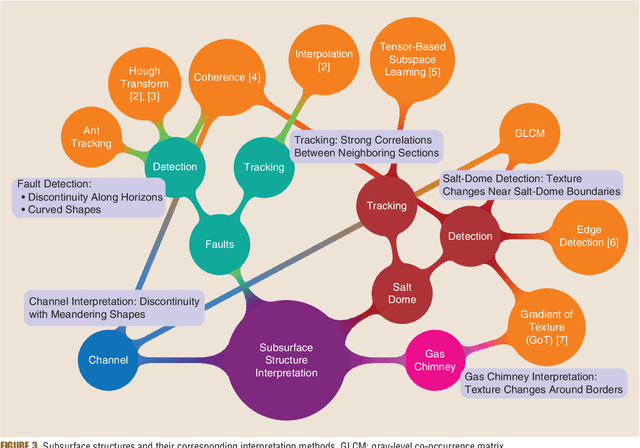
Understanding Earth's subsurface structures has been and continues to be an essential component of various applications such as environmental monitoring, carbon sequestration, and oil and gas exploration. By viewing the seismic volumes that are generated through the processing of recorded seismic traces, researchers were able to learn from applying advanced image processing and computer vision algorithms to effectively analyze and understand Earth's subsurface structures. In this paper, first, we summarize the recent advances in this direction that relied heavily on the fields of image processing and computer vision. Second, we discuss the challenges in seismic interpretation and provide insights and some directions to address such challenges using emerging machine learning algorithms.
UNIQUE: Unsupervised Image Quality Estimation
Oct 15, 2018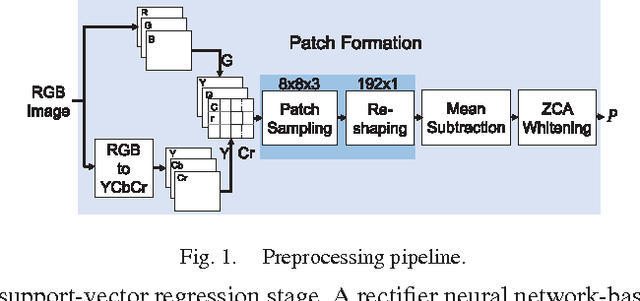
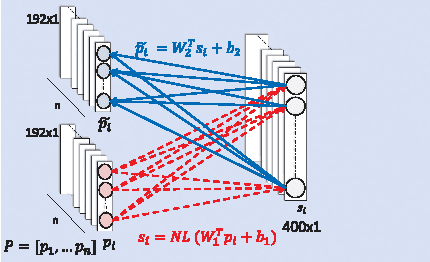
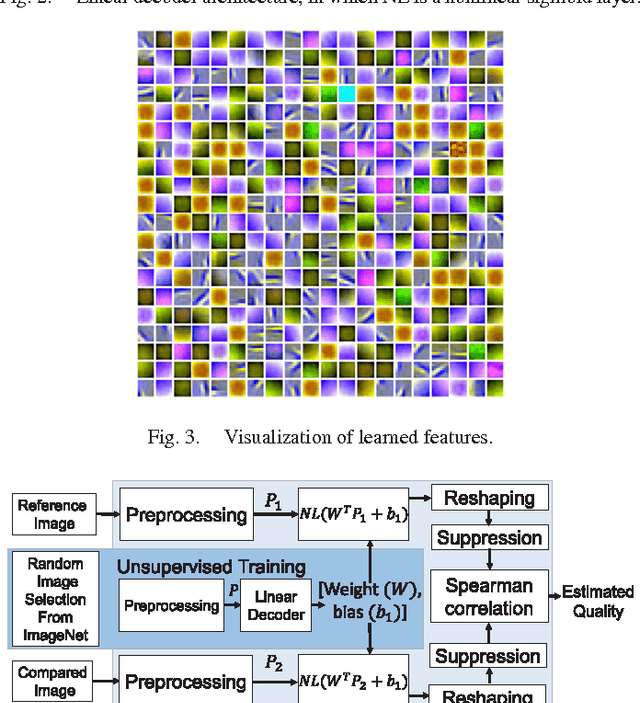
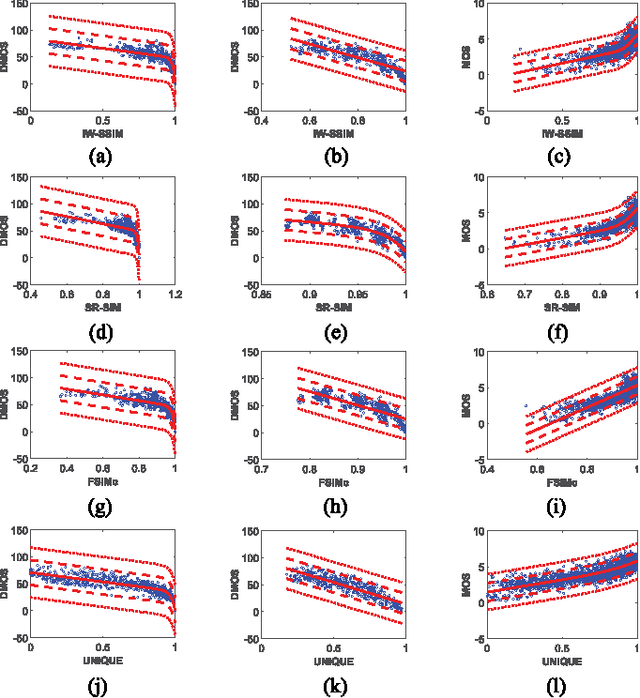
In this paper, we estimate perceived image quality using sparse representations obtained from generic image databases through an unsupervised learning approach. A color space transformation, a mean subtraction, and a whitening operation are used to enhance descriptiveness of images by reducing spatial redundancy; a linear decoder is used to obtain sparse representations; and a thresholding stage is used to formulate suppression mechanisms in a visual system. A linear decoder is trained with 7 GB worth of data, which corresponds to 100,000 8x8 image patches randomly obtained from nearly 1,000 images in the ImageNet 2013 database. A patch-wise training approach is preferred to maintain local information. The proposed quality estimator UNIQUE is tested on the LIVE, the Multiply Distorted LIVE, and the TID 2013 databases and compared with thirteen quality estimators. Experimental results show that UNIQUE is generally a top performing quality estimator in terms of accuracy, consistency, linearity, and monotonic behavior.
* 12 pages, 5 figures, 2 tables