 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling in Words on Twitter
Mar 11, 2019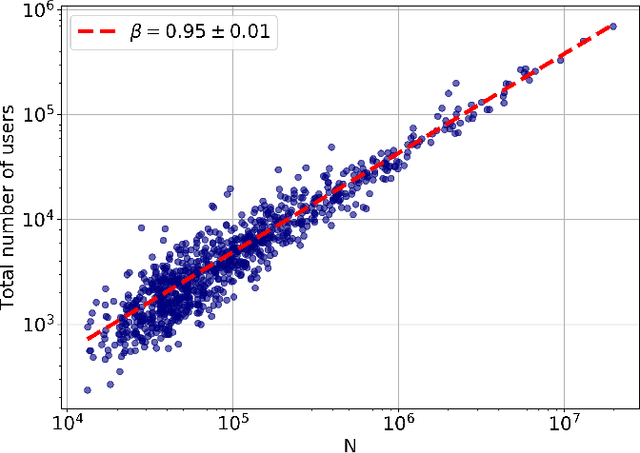
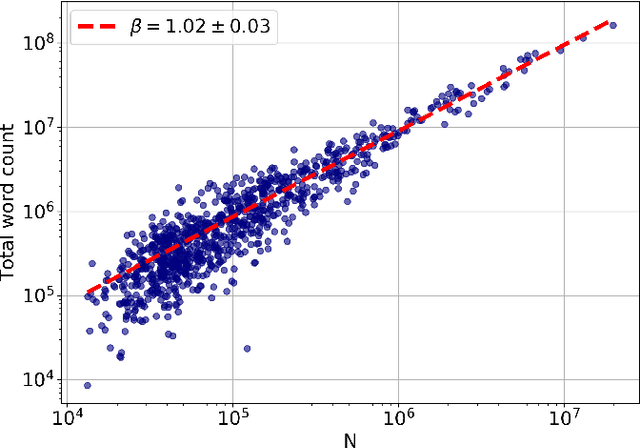
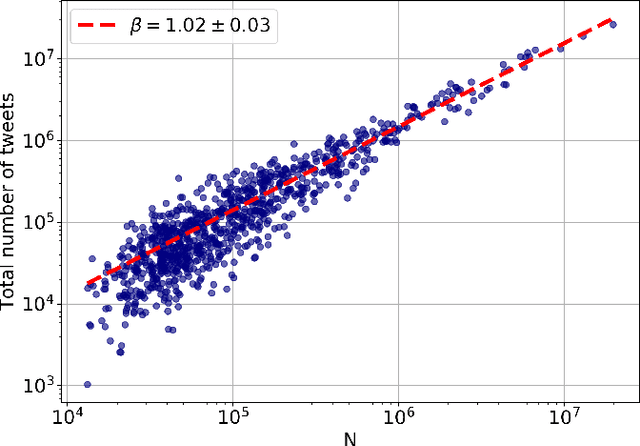
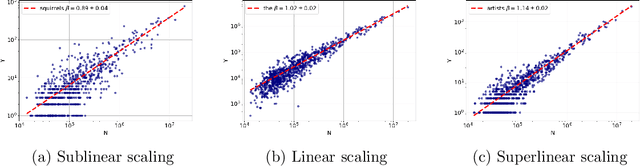
Scaling properties of language are a useful tool for understanding generative processes in texts. We investigate the scaling relations in citywise Twitter corpora coming from the Metropolitan and Micropolitan Statistical Areas of the United States. We observe a slightly superlinear urban scaling with the city population for the total volume of the tweets and words created in a city. We then find that a certain core vocabulary follows the scaling relationship of that of the bulk text, but most words are sensitive to city size, exhibiting a super- or a sublinear urban scaling. For both regimes we can offer a plausible explanation based on the meaning of the words. We also show that the parameters for Zipf's law and Heaps law differ on Twitter from that of other texts, and that the exponent of Zipf's law changes with city size.
Using Robust PCA to estimate regional characteristics of language use from geo-tagged Twitter messages
Nov 05, 2013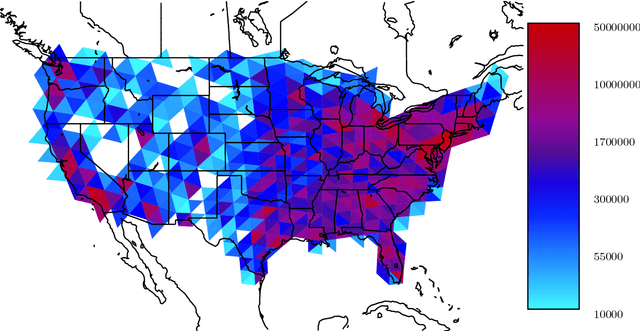
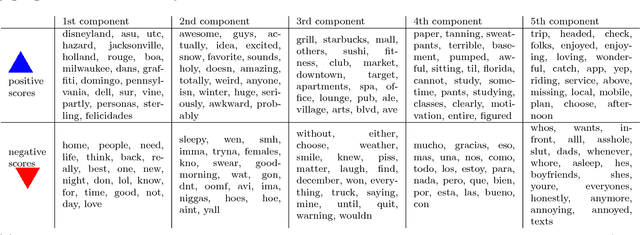
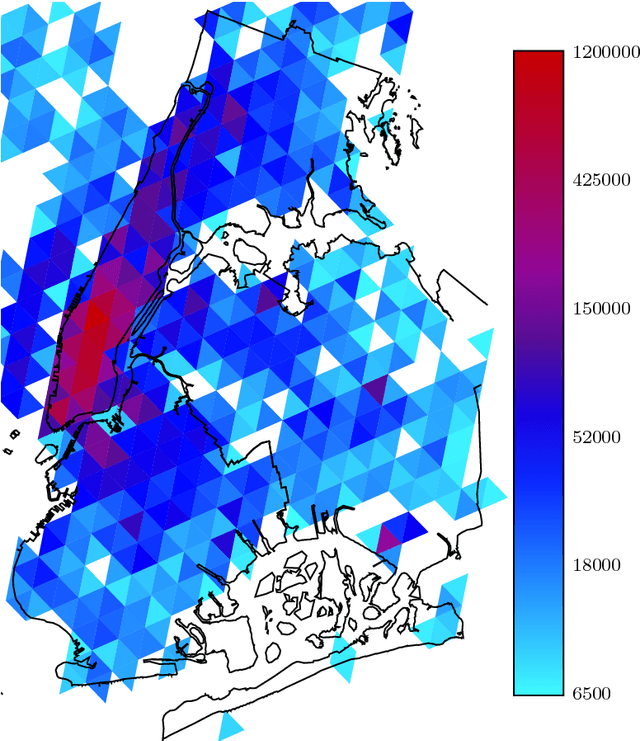
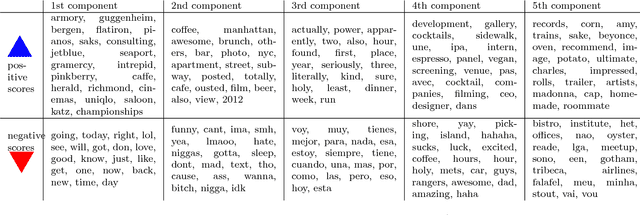
Principal component analysis (PCA) and related techniques have been successfully employed in natural language processing. Text mining applications in the age of the online social media (OSM) face new challenges due to properties specific to these use cases (e.g. spelling issues specific to texts posted by users, the presence of spammers and bots, service announcements, etc.). In this paper, we employ a Robust PCA technique to separate typical outliers and highly localized topics from the low-dimensional structure present in language use in online social networks. Our focus is on identifying geospatial features among the messages posted by the users of the Twitter microblogging service. Using a dataset which consists of over 200 million geolocated tweets collected over the course of a year, we investigate whether the information present in word usage frequencies can be used to identify regional features of language use and topics of interest. Using the PCA pursuit method, we are able to identify important low-dimensional features, which constitute smoothly varying functions of the geographic location.