 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View TRGRU: Transformer based Spatiotemporal Model for Short-Term Metro Origin-Destination Matrix Prediction
Aug 16, 2021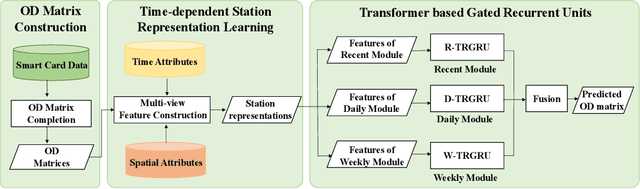



Accurate prediction of short-term OD Matrix (i.e. the distribution of passenger flows from various origins to destinations) is a crucial task in metro systems. It is highly challenging due to the constantly changing nature of many impacting factors and the real-time de- layed data collection problem. Recently, some deep learning-based models have been proposed for OD Matrix forecasting in ride- hailing and high way traffic scenarios. However, these models can not sufficiently capture the complex spatiotemporal correlation between stations in metro networks due to their different prior knowledge and contextual settings. In this paper we propose a hy- brid framework Multi-view TRGRU to address OD metro matrix prediction. In particular, it uses three modules to model three flow change patterns: recent trend, daily trend, weekly trend. In each module, a multi-view representation based on embedding for each station is constructed and fed into a transformer based gated re- current structure so as to capture the dynamic spatial dependency in OD flows of different stations by a global self-attention mecha- nism. Extensive experiments on three large-scale, real-world metro datasets demonstrate the superiority of our Multi-view TRGRU over other competitors.
Incorporating Reachability Knowledge into a Multi-Spatial Graph Convolution Based Seq2Seq Model for Traffic Forecasting
Jul 04, 2021
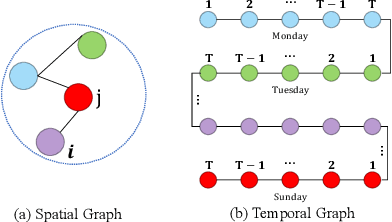


Accurate traffic state prediction is the foundation of transportation control and guidance. It is very challenging due to the complex spatiotemporal dependencies in traffic data. Existing works cannot perform well for multi-step traffic prediction that involves long future time period. The spatiotemporal information dilution becomes serve when the time gap between input step and predicted step is large, especially when traffic data is not sufficient or noisy. To address this issue, we propose a multi-spatial graph convolution based Seq2Seq model. Our main novelties are three aspects: (1) We enrich the spatiotemporal information of model inputs by fusing multi-view features (time, location and traffic states) (2) We build multiple kinds of spatial correlations based on both prior knowledge and data-driven knowledge to improve model performance especially in insufficient or noisy data cases. (3) A spatiotemporal attention mechanism based on reachability knowledge is novelly designed to produce high-level features fed into decoder of Seq2Seq directly to ease information dilution. Our model is evaluated on two real world traffic datasets and achieves better performance than other competitors.