 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNorNE: Annotating Named Entities for Norwegian
Nov 27, 2019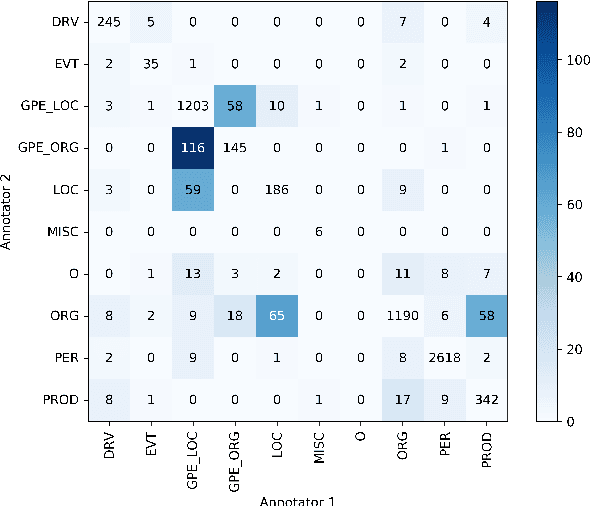
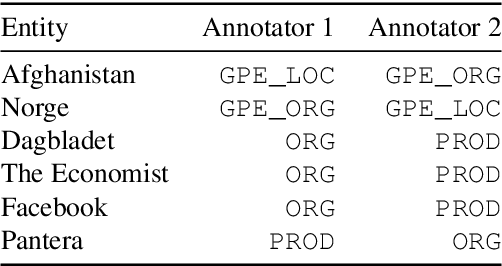
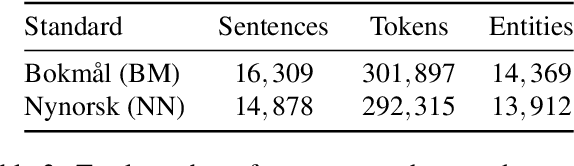

This paper presents NorNE, a manually annotated corpus of named entities which extends the annotation of the existing Norwegian Dependency Treebank. The corpus contains around 600,000 tokens taken from both varieties of written Norwegian (Bokm{\aa}l and Nynorsk) and annotates a rich set of entity types including persons, organizations, locations, geo-political entities, products, and events, in addition a class corresponding to nominals derived from a name. We here present details on the annotation effort, guidelines, inter-annotator agreement and an experimental analysis of the corpus using a neural sequence labeling architecture.
NoReC: The Norwegian Review Corpus
Oct 15, 2017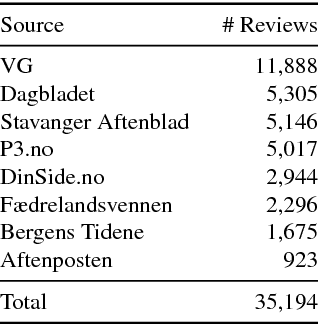
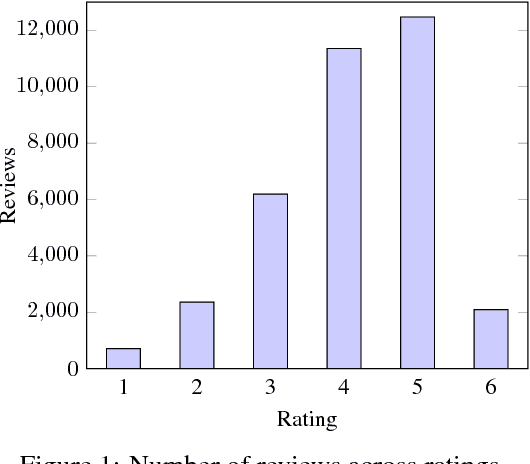

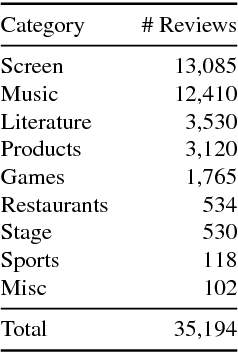
This paper presents the Norwegian Review Corpus (NoReC), created for training and evaluating models for document-level sentiment analysis. The full-text reviews have been collected from major Norwegian news sources and cover a range of different domains, including literature, movies, video games, restaurants, music and theater, in addition to product reviews across a range of categories. Each review is labeled with a manually assigned score of 1-6, as provided by the rating of the original author. This first release of the corpus comprises more than 35,000 reviews. It is distributed using the CoNLL-U format, pre-processed using UDPipe, along with a rich set of metadata. The work reported in this paper forms part of the SANT initiative (Sentiment Analysis for Norwegian Text), a project seeking to provide resources and tools for sentiment analysis and opinion mining for Norwegian. As resources for sentiment analysis have so far been unavailable for Norwegian, NoReC represents a highly valuable and sought-after addition to Norwegian language technology.