 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Correspondence Patterns to Identify Irregular Words in Cognate sets Through Leave-One-Out Validation
Feb 02, 2026Regular sound correspondences constitute the principal evidence in historical language comparison. Despite the heuristic focus on regularity, it is often more an intuitive judgement than a quantified evaluation, and irregularity is more common than expected from the Neogrammarian model. Given the recent progress of computational methods in historical linguistics and the increased availability of standardized lexical data, we are now able to improve our workflows and provide such a quantitative evaluation. Here, we present the balanced average recurrence of correspondence patterns as a new measure of regularity. We also present a new computational method that uses this measure to identify cognate sets that lack regularity with respect to their correspondence patterns. We validate the method through two experiments, using simulated and real data. In the experiments, we employ leave-one-out validation to measure the regularity of cognate sets in which one word form has been replaced by an irregular one, checking how well our method identifies the forms causing the irregularity. Our method achieves an overall accuracy of 85\% with the datasets based on real data. We also show the benefits of working with subsamples of large datasets and how increasing irregularity in the data influences our results. Reflecting on the broader potential of our new regularity measure and the irregular cognate identification method based on it, we conclude that they could play an important role in improving the quality of existing and future datasets in computer-assisted language comparison.
Over-representation of phonological features in basic vocabulary doesn't replicate when controlling for spatial and phylogenetic effects
Dec 21, 2025The statistical over-representation of phonological features in the basic vocabulary of languages is often interpreted as reflecting potentially universal sound symbolic patterns. However, most of those results have not been tested explicitly for reproducibility and might be prone to biases in the study samples or models. Many studies on the topic do not adequately control for genealogical and areal dependencies between sampled languages, casting doubts on the robustness of the results. In this study, we test the robustness of a recent study on sound symbolism of basic vocabulary concepts which analyzed 245 languages.The new sample includes data on 2864 languages from Lexibank. We modify the original model by adding statistical controls for spatial and phylogenetic dependencies between languages. The new results show that most of the previously observed patterns are not robust, and in fact many patterns disappear completely when adding the genealogical and areal controls. A small number of patterns, however, emerges as highly stable even with the new sample. Through the new analysis, we are able to assess the distribution of sound symbolism on a larger scale than previously. The study further highlights the need for testing all universal claims on language for robustness on various levels.
From Isolates to Families: Using Neural Networks for Automated Language Affiliation
Feb 17, 2025In historical linguistics, the affiliation of languages to a common language family is traditionally carried out using a complex workflow that relies on manually comparing individual languages. Large-scale standardized collections of multilingual wordlists and grammatical language structures might help to improve this and open new avenues for developing automated language affiliation workflows. Here, we present neural network models that use lexical and grammatical data from a worldwide sample of more than 1,000 languages with known affiliations to classify individual languages into families. In line with the traditional assumption of most linguists, our results show that models trained on lexical data alone outperform models solely based on grammatical data, whereas combining both types of data yields even better performance. In additional experiments, we show how our models can identify long-ranging relations between entire subgroups, how they can be employed to investigate potential relatives of linguistic isolates, and how they can help us to obtain first hints on the affiliation of so far unaffiliated languages. We conclude that models for automated language affiliation trained on lexical and grammatical data provide comparative linguists with a valuable tool for evaluating hypotheses about deep and unknown language relations.
Representing and Computing Uncertainty in Phonological Reconstruction
Oct 19, 2023Despite the inherently fuzzy nature of reconstructions in historical linguistics, most scholars do not represent their uncertainty when proposing proto-forms. With the increasing success of recently proposed approaches to automating certain aspects of the traditional comparative method, the formal representation of proto-forms has also improved. This formalization makes it possible to address both the representation and the computation of uncertainty. Building on recent advances in supervised phonological reconstruction, during which an algorithm learns how to reconstruct words in a given proto-language relying on previously annotated data, and inspired by improved methods for automated word prediction from cognate sets, we present a new framework that allows for the representation of uncertainty in linguistic reconstruction and also includes a workflow for the computation of fuzzy reconstructions from linguistic data.
Trimming Phonetic Alignments Improves the Inference of Sound Correspondence Patterns from Multilingual Wordlists
Mar 31, 2023



Sound correspondence patterns form the basis of cognate detection and phonological reconstruction in historical language comparison. Methods for the automatic inference of correspondence patterns from phonetically aligned cognate sets have been proposed, but their application to multilingual wordlists requires extremely well annotated datasets. Since annotation is tedious and time consuming, it would be desirable to find ways to improve aligned cognate data automatically. Taking inspiration from trimming techniques in evolutionary biology, which improve alignments by excluding problematic sites, we propose a workflow that trims phonetic alignments in comparative linguistics prior to the inference of correspondence patterns. Testing these techniques on a large standardized collection of ten datasets with expert annotations from different language families, we find that the best trimming technique substantially improves the overall consistency of the alignments. The results show a clear increase in the proportion of frequent correspondence patterns and words exhibiting regular cognate relations.
Building an Endangered Language Resource in the Classroom: Universal Dependencies for Kakataibo
Jun 21, 2022
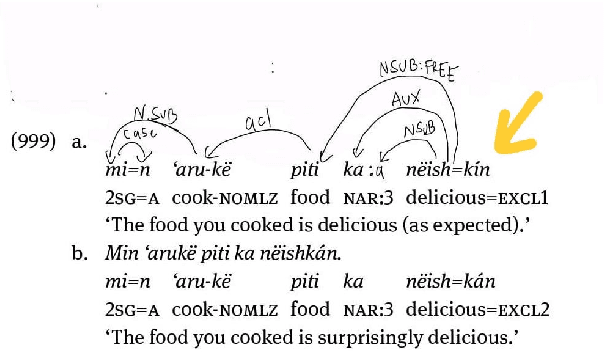
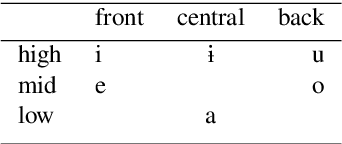
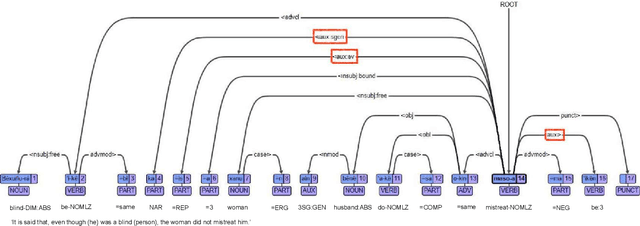
In this paper, we launch a new Universal Dependencies treebank for an endangered language from Amazonia: Kakataibo, a Panoan language spoken in Peru. We first discuss the collaborative methodology implemented, which proved effective to create a treebank in the context of a Computational Linguistic course for undergraduates. Then, we describe the general details of the treebank and the language-specific considerations implemented for the proposed annotation. We finally conduct some experiments on part-of-speech tagging and syntactic dependency parsing. We focus on monolingual and transfer learning settings, where we study the impact of a Shipibo-Konibo treebank, another Panoan language resource.