 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCongruence-based Learning of Probabilistic Deterministic Finite Automata
Dec 12, 2024This work studies the question of learning probabilistic deterministic automata from language models. For this purpose, it focuses on analyzing the relations defined on algebraic structures over strings by equivalences and similarities on probability distributions. We introduce a congruence that extends the classical Myhill-Nerode congruence for formal languages. This new congruence is the basis for defining regularity over language models. We present an active learning algorithm that computes the quotient with respect to this congruence whenever the language model is regular. The paper also defines the notion of recognizability for language models and shows that it coincides with regularity for congruences. For relations which are not congruences, it shows that this is not the case. Finally, it discusses the impact of this result on learning in the context of language models.
Analyzing constrained LLM through PDFA-learning
Jun 12, 2024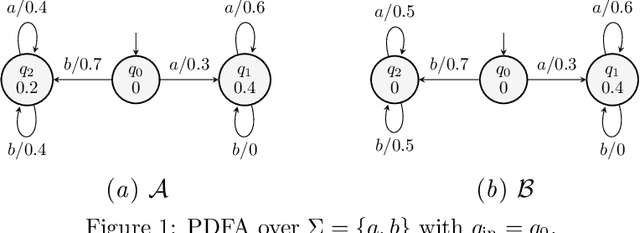
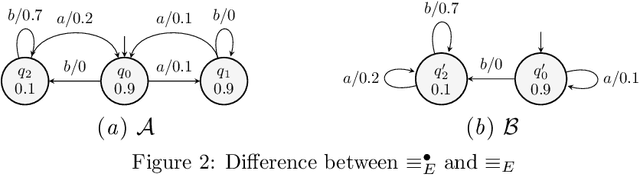

We define a congruence that copes with null next-symbol probabilities that arise when the output of a language model is constrained by some means during text generation. We develop an algorithm for efficiently learning the quotient with respect to this congruence and evaluate it on case studies for analyzing statistical properties of LLM.
Towards Efficient Active Learning of PDFA
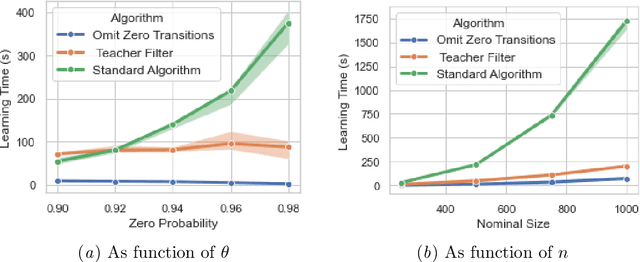
Jun 17, 2022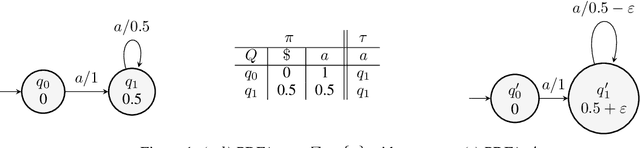
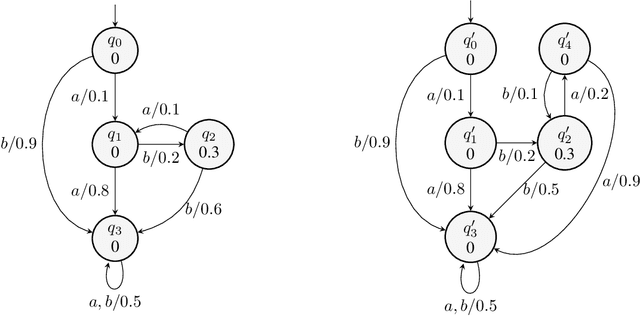
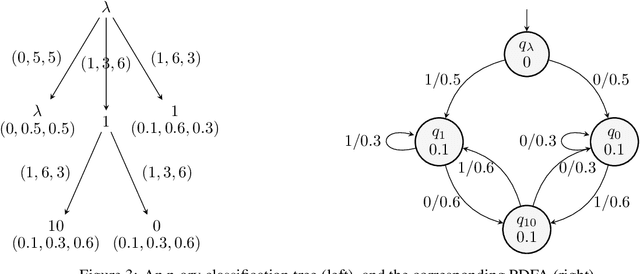
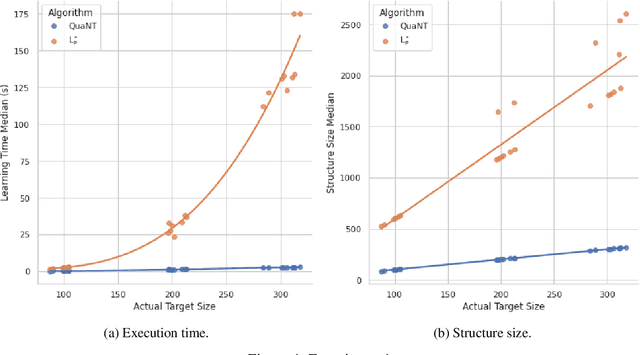
We propose a new active learning algorithm for PDFA based on three main aspects: a congruence over states which takes into account next-symbol probability distributions, a quantization that copes with differences in distributions, and an efficient tree-based data structure. Experiments showed significant performance gains with respect to reference implementations.