Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing constrained LLM through PDFA-learning
Jun 12, 2024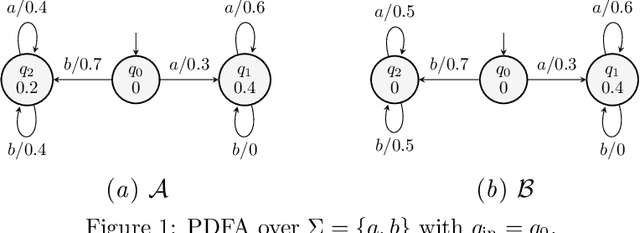
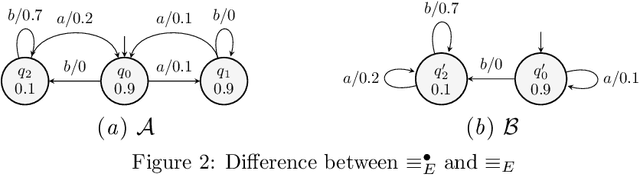

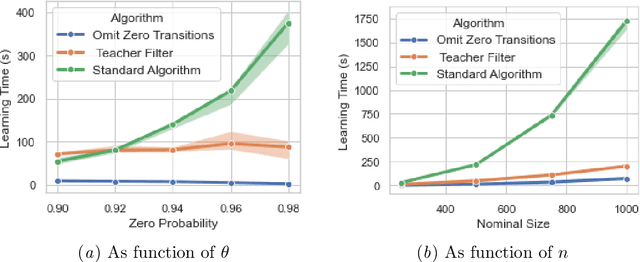
We define a congruence that copes with null next-symbol probabilities that arise when the output of a language model is constrained by some means during text generation. We develop an algorithm for efficiently learning the quotient with respect to this congruence and evaluate it on case studies for analyzing statistical properties of LLM.
* Workshop Paper
Via