 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Classification and Feature Selection from Finite Data Sets
Jan 16, 2013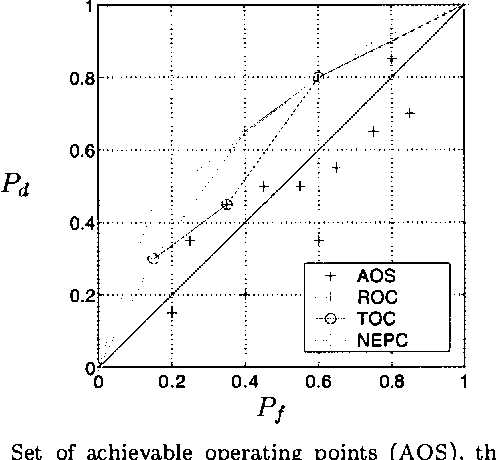
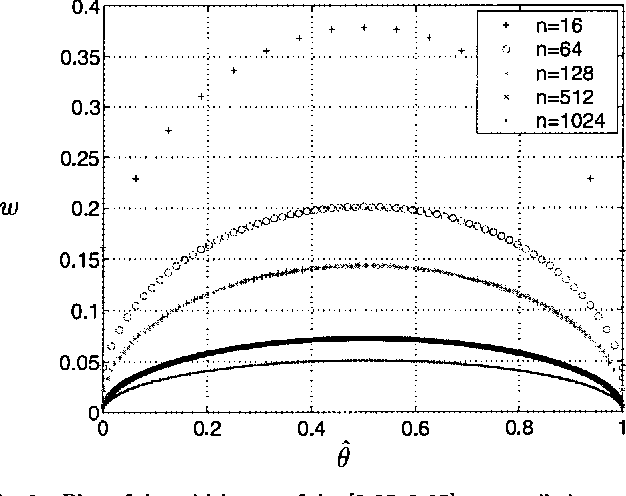
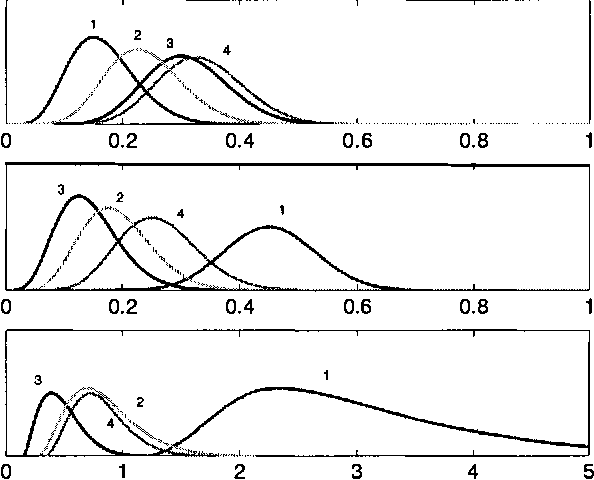
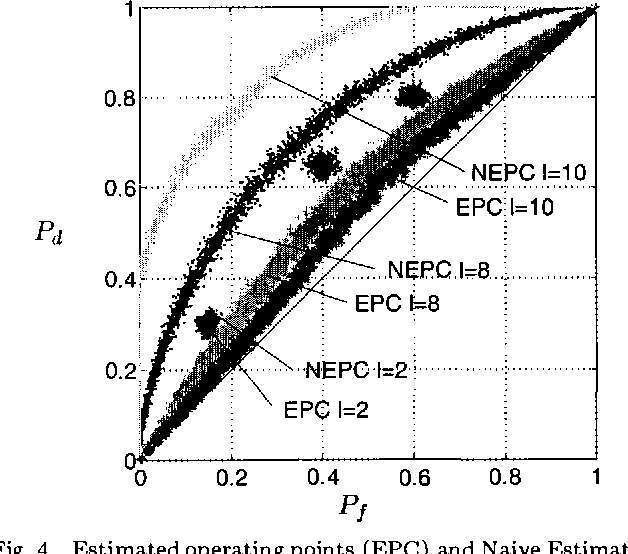
Feature selection aims to select the smallest subset of features for a specified level of performance. The optimal achievable classification performance on a feature subset is summarized by its Receiver Operating Curve (ROC). When infinite data is available, the Neyman- Pearson (NP) design procedure provides the most efficient way of obtaining this curve. In practice the design procedure is applied to density estimates from finite data sets. We perform a detailed statistical analysis of the resulting error propagation on finite alphabets. We show that the estimated performance curve (EPC) produced by the design procedure is arbitrarily accurate given sufficient data, independent of the size of the feature set. However, the underlying likelihood ranking procedure is highly sensitive to errors that reduces the probability that the EPC is in fact the ROC. In the worst case, guaranteeing that the EPC is equal to the ROC may require data sizes exponential in the size of the feature set. These results imply that in theory the NP design approach may only be valid for characterizing relatively small feature subsets, even when the performance of any given classifier can be estimated very accurately. We discuss the practical limitations for on-line methods that ensures that the NP procedure operates in a statistically valid region.