 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan a Tabula Recta provide security in the XXI century?
Dec 05, 2023In the not so unlikely scenario of total compromise of computers accessible to a group of users, they might be tempted to resort to human-computable paper-and-pencil cryptographic methods aided by a classic Tabula Recta, which helps to perform addition and subtraction directly with letters. But do these classic algorithms, or some new ones using the same simple tools, have any chance against computer-aided cryptanalysis? In this paper I discuss how some human-computable algorithms can indeed afford sufficient security in this situation, drawing conclusions from computer-based statistical analysis. Three kinds of algorithms are discussed: those that concentrate entropy from shared text sources, stream ciphers based on arithmetic of non-binary spaces, and hash-like algorithms that may be used to generate a password from a challenge text.
Estimating Heterogeneous Consumer Preferences for Restaurants and Travel Time Using Mobile Location Data
Jan 22, 2018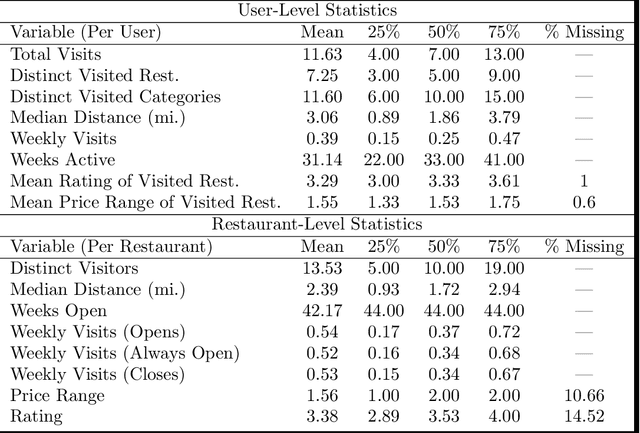
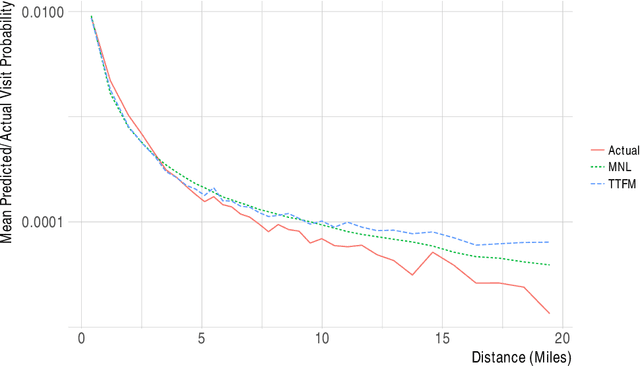
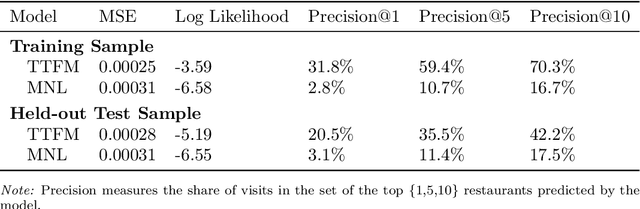
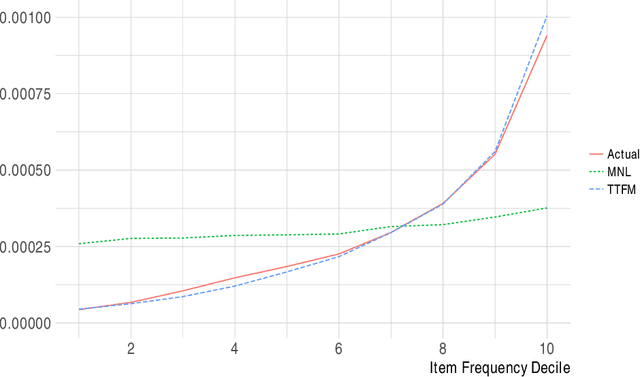
This paper analyzes consumer choices over lunchtime restaurants using data from a sample of several thousand anonymous mobile phone users in the San Francisco Bay Area. The data is used to identify users' approximate typical morning location, as well as their choices of lunchtime restaurants. We build a model where restaurants have latent characteristics (whose distribution may depend on restaurant observables, such as star ratings, food category, and price range), each user has preferences for these latent characteristics, and these preferences are heterogeneous across users. Similarly, each item has latent characteristics that describe users' willingness to travel to the restaurant, and each user has individual-specific preferences for those latent characteristics. Thus, both users' willingness to travel and their base utility for each restaurant vary across user-restaurant pairs. We use a Bayesian approach to estimation. To make the estimation computationally feasible, we rely on variational inference to approximate the posterior distribution, as well as stochastic gradient descent as a computational approach. Our model performs better than more standard competing models such as multinomial logit and nested logit models, in part due to the personalization of the estimates. We analyze how consumers re-allocate their demand after a restaurant closes to nearby restaurants versus more distant restaurants with similar characteristics, and we compare our predictions to actual outcomes. Finally, we show how the model can be used to analyze counterfactual questions such as what type of restaurant would attract the most consumers in a given location.
Structured Embedding Models for Grouped Data
Sep 28, 2017

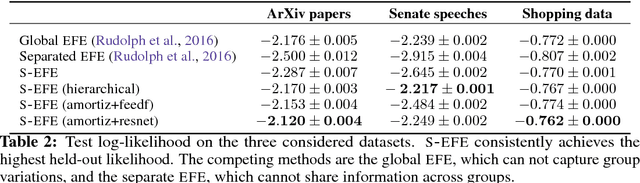

Word embeddings are a powerful approach for analyzing language, and exponential family embeddings (EFE) extend them to other types of data. Here we develop structured exponential family embeddings (S-EFE), a method for discovering embeddings that vary across related groups of data. We study how the word usage of U.S. Congressional speeches varies across states and party affiliation, how words are used differently across sections of the ArXiv, and how the co-purchase patterns of groceries can vary across seasons. Key to the success of our method is that the groups share statistical information. We develop two sharing strategies: hierarchical modeling and amortization. We demonstrate the benefits of this approach in empirical studies of speeches, abstracts, and shopping baskets. We show how S-EFE enables group-specific interpretation of word usage, and outperforms EFE in predicting held-out data.