 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-dimensional Embodied Semantics for Music and Language
Jun 20, 2019
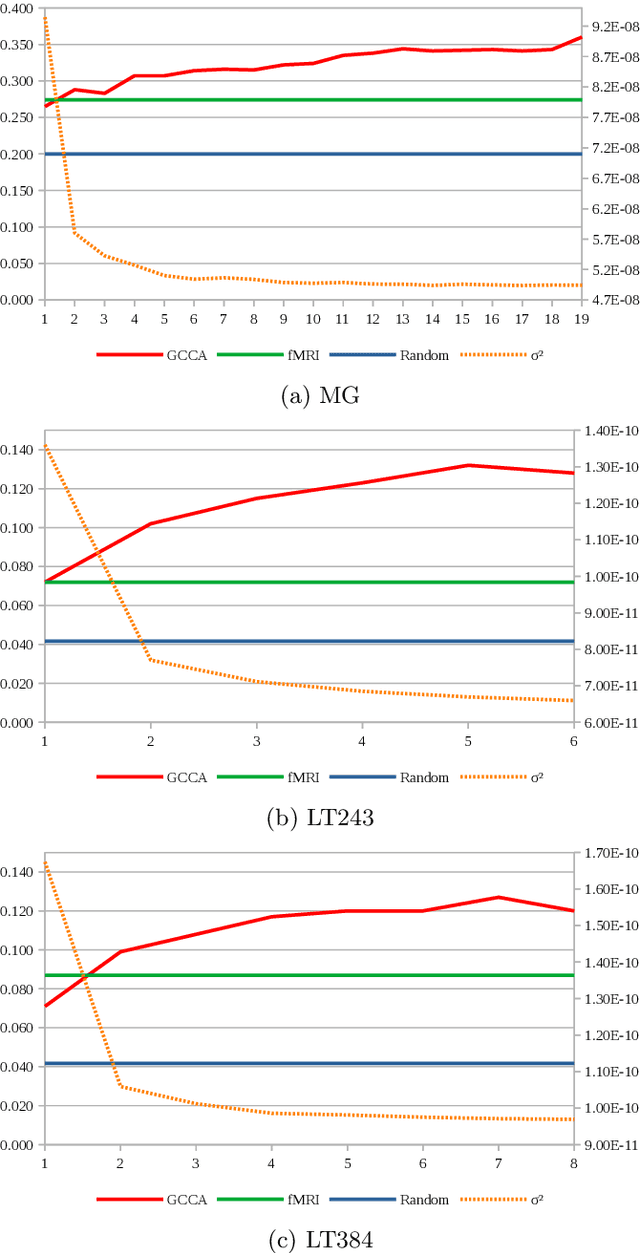
Embodied cognition states that semantics is encoded in the brain as firing patterns of neural circuits, which are learned according to the statistical structure of human multimodal experience. However, each human brain is idiosyncratically biased, according to its subjective experience history, making this biological semantic machinery noisy with respect to the overall semantics inherent to media artifacts, such as music and language excerpts. We propose to represent shared semantics using low-dimensional vector embeddings by jointly modeling several brains from human subjects. We show these unsupervised efficient representations outperform the original high-dimensional fMRI voxel spaces in proxy music genre and language topic classification tasks. We further show that joint modeling of several subjects increases the semantic richness of the learned latent vector spaces.
Learning Embodied Semantics via Music and Dance Semiotic Correlations
Mar 25, 2019
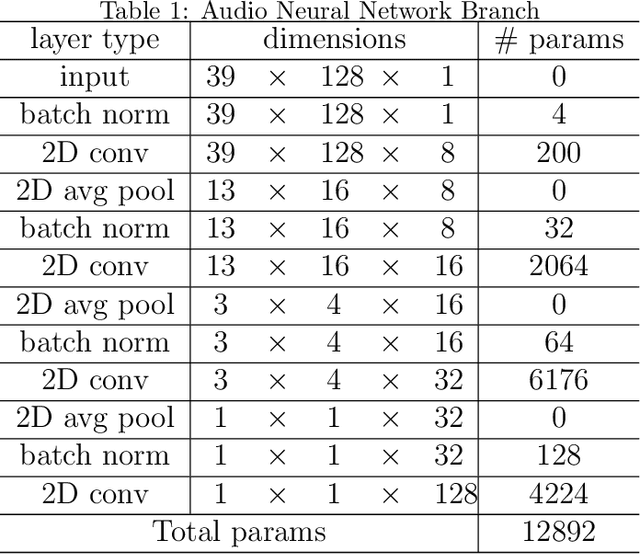
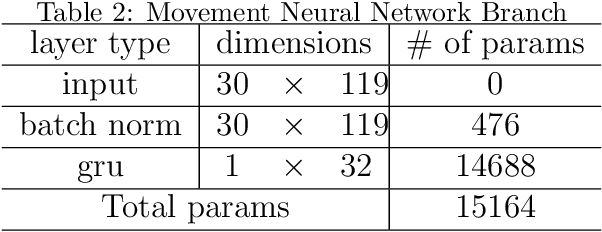

Music semantics is embodied, in the sense that meaning is biologically mediated by and grounded in the human body and brain. This embodied cognition perspective also explains why music structures modulate kinetic and somatosensory perception. We leverage this aspect of cognition, by considering dance as a proxy for music perception, in a statistical computational model that learns semiotic correlations between music audio and dance video. We evaluate the ability of this model to effectively capture underlying semantics in a cross-modal retrieval task. Quantitative results, validated with statistical significance testing, strengthen the body of evidence for embodied cognition in music and show the model can recommend music audio for dance video queries and vice-versa.