 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransductive Learning for Near-Duplicate Image Detection in Scanned Photo Collections
Oct 25, 2024This paper presents a comparative study of near-duplicate image detection techniques in a real-world use case scenario, where a document management company is commissioned to manually annotate a collection of scanned photographs. Detecting duplicate and near-duplicate photographs can reduce the time spent on manual annotation by archivists. This real use case differs from laboratory settings as the deployment dataset is available in advance, allowing the use of transductive learning. We propose a transductive learning approach that leverages state-of-the-art deep learning architectures such as convolutional neural networks (CNNs) and Vision Transformers (ViTs). Our approach involves pre-training a deep neural network on a large dataset and then fine-tuning the network on the unlabeled target collection with self-supervised learning. The results show that the proposed approach outperforms the baseline methods in the task of near-duplicate image detection in the UKBench and an in-house private dataset.
EUFCC-CIR: a Composed Image Retrieval Dataset for GLAM Collections
Oct 02, 2024



The intersection of Artificial Intelligence and Digital Humanities enables researchers to explore cultural heritage collections with greater depth and scale. In this paper, we present EUFCC-CIR, a dataset designed for Composed Image Retrieval (CIR) within Galleries, Libraries, Archives, and Museums (GLAM) collections. Our dataset is built on top of the EUFCC-340K image labeling dataset and contains over 180K annotated CIR triplets. Each triplet is composed of a multi-modal query (an input image plus a short text describing the desired attribute manipulations) and a set of relevant target images. The EUFCC-CIR dataset fills an existing gap in CIR-specific resources for Digital Humanities. We demonstrate the value of the EUFCC-CIR dataset by highlighting its unique qualities in comparison to other existing CIR datasets and evaluating the performance of several zero-shot CIR baselines.
EUFCC-340K: A Faceted Hierarchical Dataset for Metadata Annotation in GLAM Collections
Jun 04, 2024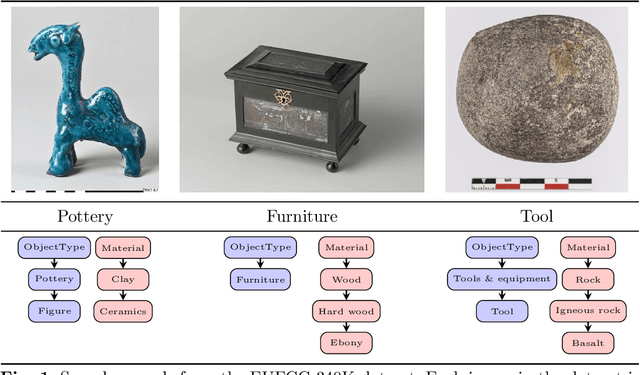
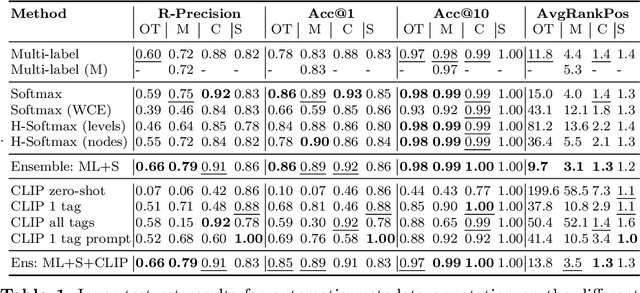

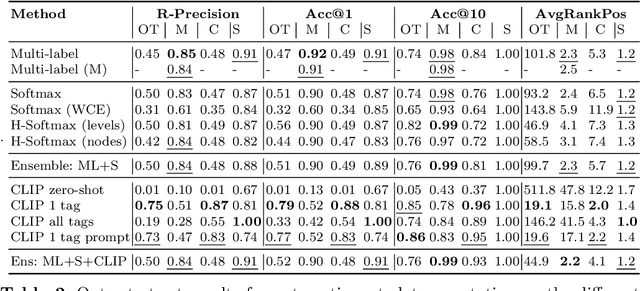
In this paper, we address the challenges of automatic metadata annotation in the domain of Galleries, Libraries, Archives, and Museums (GLAMs) by introducing a novel dataset, EUFCC340K, collected from the Europeana portal. Comprising over 340,000 images, the EUFCC340K dataset is organized across multiple facets: Materials, Object Types, Disciplines, and Subjects, following a hierarchical structure based on the Art & Architecture Thesaurus (AAT). We developed several baseline models, incorporating multiple heads on a ConvNeXT backbone for multi-label image tagging on these facets, and fine-tuning a CLIP model with our image text pairs. Our experiments to evaluate model robustness and generalization capabilities in two different test scenarios demonstrate the utility of the dataset in improving multi-label classification tools that have the potential to alleviate cataloging tasks in the cultural heritage sector.
TrackNet: A Triplet metric-based method for Multi-Target Multi-Camera Vehicle Tracking
May 27, 2022
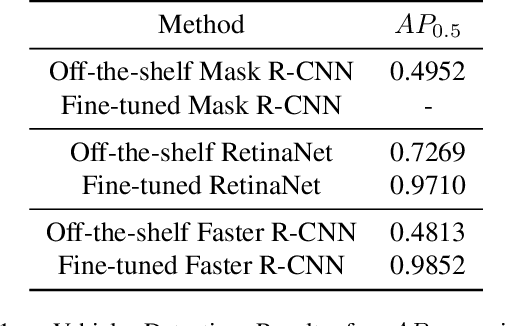
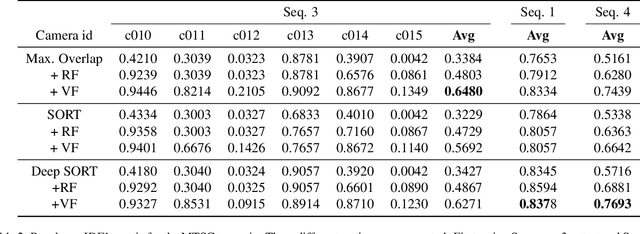

We present TrackNet, a method for Multi-Target Multi-Camera (MTMC) vehicle tracking from traffic video sequences. Cross-camera vehicle tracking has proved to be a challenging task due to perspective, scale and speed variance, as well occlusions and noise conditions. Our method is based on a modular approach that first detects vehicles frame-by-frame using Faster R-CNN, then tracks detections through single camera using Kalman filter, and finally matches tracks by a triplet metric learning strategy. We conduct experiments on TrackNet within the AI City Challenge framework, and present competitive IDF1 results of 0.4733.