 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Data Quality-Driven Framework for Machine Learning in Production Environment
Dec 16, 2025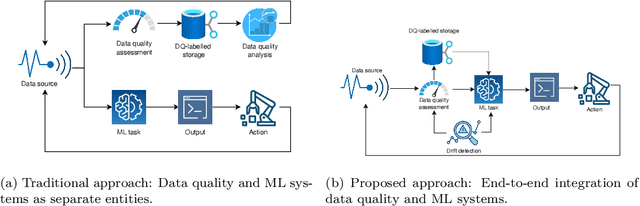



This paper introduces a novel end-to-end framework that efficiently integrates data quality assessment with machine learning (ML) model operations in real-time production environments. While existing approaches treat data quality assessment and ML systems as isolated processes, our framework addresses the critical gap between theoretical methods and practical implementation by combining dynamic drift detection, adaptive data quality metrics, and MLOps into a cohesive, lightweight system. The key innovation lies in its operational efficiency, enabling real-time, quality-driven ML decision-making with minimal computational overhead. We validate the framework in a steel manufacturing company's Electroslag Remelting (ESR) vacuum pumping process, demonstrating a 12% improvement in model performance (R2 = 94%) and a fourfold reduction in prediction latency. By exploring the impact of data quality acceptability thresholds, we provide actionable insights into balancing data quality standards and predictive performance in industrial applications. This framework represents a significant advancement in MLOps, offering a robust solution for time-sensitive, data-driven decision-making in dynamic industrial environments.
* 38 Pages
Towards Trustworthy Machine Learning in Production: An Overview of the Robustness in MLOps Approach
Oct 28, 2024Artificial intelligence (AI), and especially its sub-field of Machine Learning (ML), are impacting the daily lives of everyone with their ubiquitous applications. In recent years, AI researchers and practitioners have introduced principles and guidelines to build systems that make reliable and trustworthy decisions. From a practical perspective, conventional ML systems process historical data to extract the features that are consequently used to train ML models that perform the desired task. However, in practice, a fundamental challenge arises when the system needs to be operationalized and deployed to evolve and operate in real-life environments continuously. To address this challenge, Machine Learning Operations (MLOps) have emerged as a potential recipe for standardizing ML solutions in deployment. Although MLOps demonstrated great success in streamlining ML processes, thoroughly defining the specifications of robust MLOps approaches remains of great interest to researchers and practitioners. In this paper, we provide a comprehensive overview of the trustworthiness property of MLOps systems. Specifically, we highlight technical practices to achieve robust MLOps systems. In addition, we survey the existing research approaches that address the robustness aspects of ML systems in production. We also review the tools and software available to build MLOps systems and summarize their support to handle the robustness aspects. Finally, we present the open challenges and propose possible future directions and opportunities within this emerging field. The aim of this paper is to provide researchers and practitioners working on practical AI applications with a comprehensive view to adopt robust ML solutions in production environments.
Adaptive Data Quality Scoring Operations Framework using Drift-Aware Mechanism for Industrial Applications
Aug 13, 2024Within data-driven artificial intelligence (AI) systems for industrial applications, ensuring the reliability of the incoming data streams is an integral part of trustworthy decision-making. An approach to assess data validity is data quality scoring, which assigns a score to each data point or stream based on various quality dimensions. However, certain dimensions exhibit dynamic qualities, which require adaptation on the basis of the system's current conditions. Existing methods often overlook this aspect, making them inefficient in dynamic production environments. In this paper, we introduce the Adaptive Data Quality Scoring Operations Framework, a novel framework developed to address the challenges posed by dynamic quality dimensions in industrial data streams. The framework introduces an innovative approach by integrating a dynamic change detector mechanism that actively monitors and adapts to changes in data quality, ensuring the relevance of quality scores. We evaluate the proposed framework performance in a real-world industrial use case. The experimental results reveal high predictive performance and efficient processing time, highlighting its effectiveness in practical quality-driven AI applications.
* 17 pages
DA-LSTM: A Dynamic Drift-Adaptive Learning Framework for Interval Load Forecasting with LSTM Networks
May 15, 2023Load forecasting is a crucial topic in energy management systems (EMS) due to its vital role in optimizing energy scheduling and enabling more flexible and intelligent power grid systems. As a result, these systems allow power utility companies to respond promptly to demands in the electricity market. Deep learning (DL) models have been commonly employed in load forecasting problems supported by adaptation mechanisms to cope with the changing pattern of consumption by customers, known as concept drift. A drift magnitude threshold should be defined to design change detection methods to identify drifts. While the drift magnitude in load forecasting problems can vary significantly over time, existing literature often assumes a fixed drift magnitude threshold, which should be dynamically adjusted rather than fixed during system evolution. To address this gap, in this paper, we propose a dynamic drift-adaptive Long Short-Term Memory (DA-LSTM) framework that can improve the performance of load forecasting models without requiring a drift threshold setting. We integrate several strategies into the framework based on active and passive adaptation approaches. To evaluate DA-LSTM in real-life settings, we thoroughly analyze the proposed framework and deploy it in a real-world problem through a cloud-based environment. Efficiency is evaluated in terms of the prediction performance of each approach and computational cost. The experiments show performance improvements on multiple evaluation metrics achieved by our framework compared to baseline methods from the literature. Finally, we present a trade-off analysis between prediction performance and computational costs.
A Domain-Region Based Evaluation of ML Performance Robustness to Covariate Shift
Apr 18, 2023Most machine learning methods assume that the input data distribution is the same in the training and testing phases. However, in practice, this stationarity is usually not met and the distribution of inputs differs, leading to unexpected performance of the learned model in deployment. The issue in which the training and test data inputs follow different probability distributions while the input-output relationship remains unchanged is referred to as covariate shift. In this paper, the performance of conventional machine learning models was experimentally evaluated in the presence of covariate shift. Furthermore, a region-based evaluation was performed by decomposing the domain of probability density function of the input data to assess the classifier's performance per domain region. Distributional changes were simulated in a two-dimensional classification problem. Subsequently, a higher four-dimensional experiments were conducted. Based on the experimental analysis, the Random Forests algorithm is the most robust classifier in the two-dimensional case, showing the lowest degradation rate for accuracy and F1-score metrics, with a range between 0.1% and 2.08%. Moreover, the results reveal that in higher-dimensional experiments, the performance of the models is predominantly influenced by the complexity of the classification function, leading to degradation rates exceeding 25% in most cases. It is also concluded that the models exhibit high bias towards the region with high density in the input space domain of the training samples.
From Concept Drift to Model Degradation: An Overview on Performance-Aware Drift Detectors
Mar 21, 2022
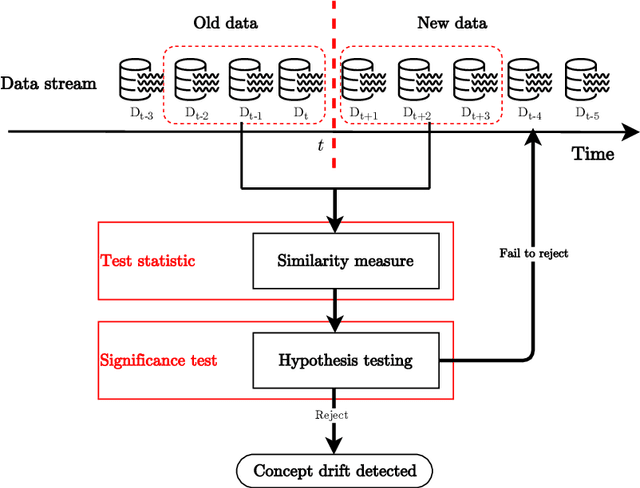
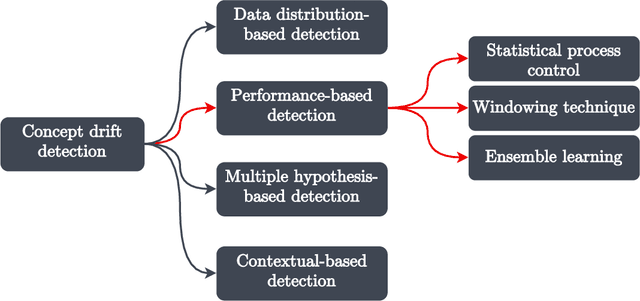
The dynamicity of real-world systems poses a significant challenge to deployed predictive machine learning (ML) models. Changes in the system on which the ML model has been trained may lead to performance degradation during the system's life cycle. Recent advances that study non-stationary environments have mainly focused on identifying and addressing such changes caused by a phenomenon called concept drift. Different terms have been used in the literature to refer to the same type of concept drift and the same term for various types. This lack of unified terminology is set out to create confusion on distinguishing between different concept drift variants. In this paper, we start by grouping concept drift types by their mathematical definitions and survey the different terms used in the literature to build a consolidated taxonomy of the field. We also review and classify performance-based concept drift detection methods proposed in the last decade. These methods utilize the predictive model's performance degradation to signal substantial changes in the systems. The classification is outlined in a hierarchical diagram to provide an orderly navigation between the methods. We present a comprehensive analysis of the main attributes and strategies for tracking and evaluating the model's performance in the predictive system. The paper concludes by discussing open research challenges and possible research directions.