 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloud Kitchen: Using Planning-based Composite AI to Optimize Food Delivery Process
Feb 16, 2024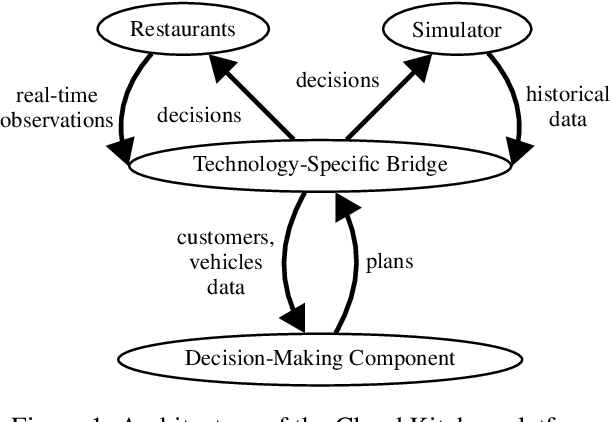
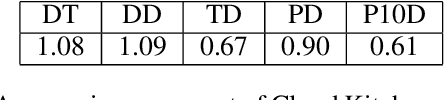
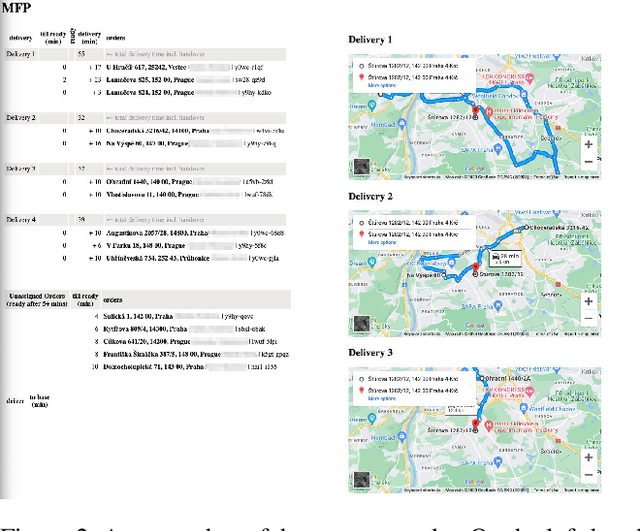
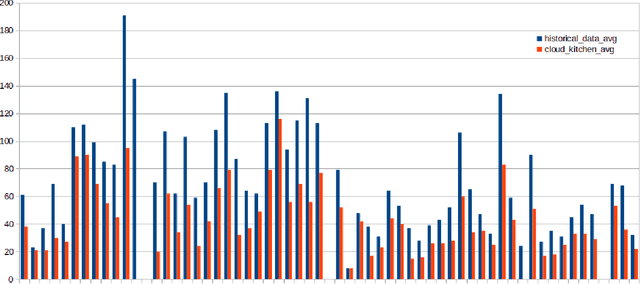
The global food delivery market provides many opportunities for AI-based services that can improve the efficiency of feeding the world. This paper presents the Cloud Kitchen platform as a decision-making tool for restaurants with food delivery and a simulator to evaluate the impact of the decisions. The platform consists of a Technology-Specific Bridge (TSB) that provides an interface for communicating with restaurants or the simulator. TSB uses a PDDL model to represent decisions embedded in the Unified Planning Framework (UPF). Decision-making, which concerns allocating customers' orders to vehicles and deciding in which order the customers will be served (for each vehicle), is done via a Vehicle Routing Problem with Time Windows (VRPTW), an efficient tool for this problem. We show that decisions made by our platform can improve customer satisfaction by reducing the number of delayed deliveries using a real-world historical dataset.
Learning Planning Action Models from State Traces
Feb 16, 2024

Previous STRIPS domain model acquisition approaches that learn from state traces start with the names and parameters of the actions to be learned. Therefore their only task is to deduce the preconditions and effects of the given actions. In this work, we explore learning in situations when the parameters of learned actions are not provided. We define two levels of trace quality based on which information is provided and present an algorithm for each. In one level (L1), the states in the traces are labeled with action names, so we can deduce the number and names of the actions, but we still need to work out the number and types of parameters. In the other level (L2), the states are additionally labeled with objects that constitute the parameters of the corresponding grounded actions. Here we still need to deduce the types of the parameters in the learned actions. We experimentally evaluate the proposed algorithms and compare them with the state-of-the-art learning tool FAMA on a large collection of IPC benchmarks. The evaluation shows that our new algorithms are faster, can handle larger inputs and provide better results in terms of learning action models more similar to reference models.
On Automating Video Game Testing by Planning and Learning
Feb 16, 2024



In this paper, we propose a method and workflow for automating the testing of certain video game aspects using automated planning and planning action model learning techniques. The basic idea is to generate detailed gameplay logs and apply action model learning to obtain a formal model in the planning domain description language (PDDL). The workflow enables efficient cooperation of game developers without any experience with PDDL or other formal systems and a person experienced with PDDL modeling but no game development skills. We describe the method and workflow in general and then demonstrate it on a concrete proof-of-concept example -- a simple role-playing game provided as one of the tutorial projects in the popular game development engine Unity. This paper presents the first step towards minimizing or even eliminating the need for a modeling expert in the workflow, thus making automated planning accessible to a broader audience.