 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-native Memory 2.0: Second Me
Mar 11, 2025Human interaction with the external world fundamentally involves the exchange of personal memory, whether with other individuals, websites, applications, or, in the future, AI agents. A significant portion of this interaction is redundant, requiring users to repeatedly provide the same information across different contexts. Existing solutions, such as browser-stored credentials, autofill mechanisms, and unified authentication systems, have aimed to mitigate this redundancy by serving as intermediaries that store and retrieve commonly used user data. The advent of large language models (LLMs) presents an opportunity to redefine memory management through an AI-native paradigm: SECOND ME. SECOND ME acts as an intelligent, persistent memory offload system that retains, organizes, and dynamically utilizes user-specific knowledge. By serving as an intermediary in user interactions, it can autonomously generate context-aware responses, prefill required information, and facilitate seamless communication with external systems, significantly reducing cognitive load and interaction friction. Unlike traditional memory storage solutions, SECOND ME extends beyond static data retention by leveraging LLM-based memory parameterization. This enables structured organization, contextual reasoning, and adaptive knowledge retrieval, facilitating a more systematic and intelligent approach to memory management. As AI-driven personal agents like SECOND ME become increasingly integrated into digital ecosystems, SECOND ME further represents a critical step toward augmenting human-world interaction with persistent, contextually aware, and self-optimizing memory systems. We have open-sourced the fully localizable deployment system at GitHub: https://github.com/Mindverse/Second-Me.
AI-native Memory: A Pathway from LLMs Towards AGI
Jun 26, 2024
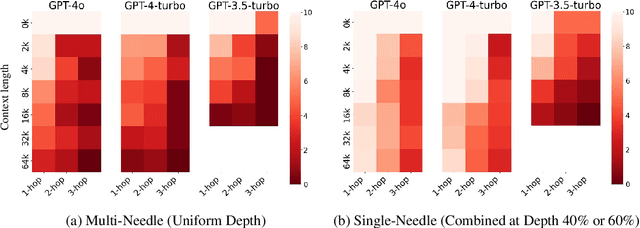


Large language models (LLMs) have demonstrated the world with the sparks of artificial general intelligence (AGI). One opinion, especially from some startups working on LLMs, argues that an LLM with nearly unlimited context length can realize AGI. However, they might be too optimistic about the long-context capability of (existing) LLMs -- (1) Recent literature has shown that their effective context length is significantly smaller than their claimed context length; and (2) Our reasoning-in-a-haystack experiments further demonstrate that simultaneously finding the relevant information from a long context and conducting (simple) reasoning is nearly impossible. In this paper, we envision a pathway from LLMs to AGI through the integration of \emph{memory}. We believe that AGI should be a system where LLMs serve as core processors. In addition to raw data, the memory in this system would store a large number of important conclusions derived from reasoning processes. Compared with retrieval-augmented generation (RAG) that merely processing raw data, this approach not only connects semantically related information closer, but also simplifies complex inferences at the time of querying. As an intermediate stage, the memory will likely be in the form of natural language descriptions, which can be directly consumed by users too. Ultimately, every agent/person should have its own large personal model, a deep neural network model (thus \emph{AI-native}) that parameterizes and compresses all types of memory, even the ones cannot be described by natural languages. Finally, we discuss the significant potential of AI-native memory as the transformative infrastructure for (proactive) engagement, personalization, distribution, and social in the AGI era, as well as the incurred privacy and security challenges with preliminary solutions.