 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Structure Learning for Sparse Context-Specific Causal Systems
Feb 12, 2024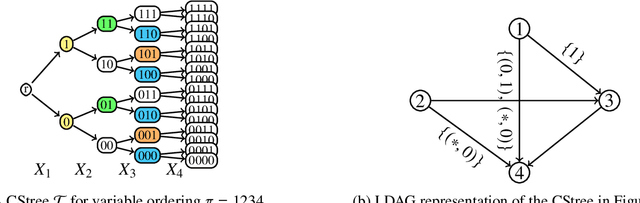

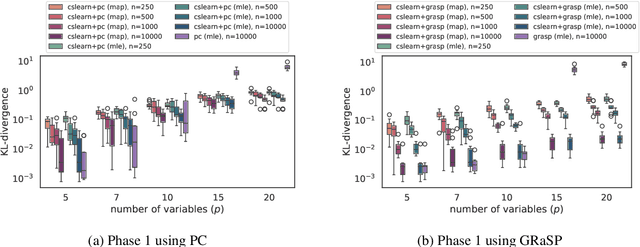
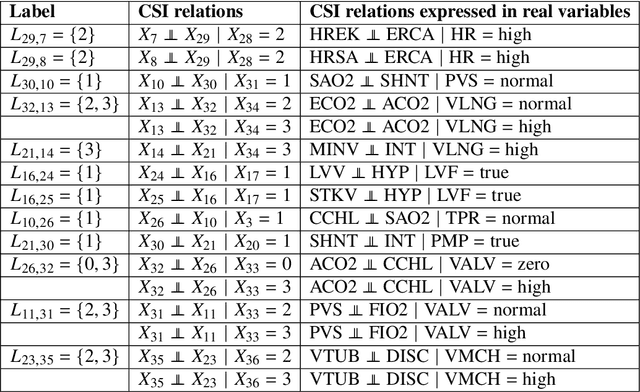
Several approaches to graphically representing context-specific relations among jointly distributed categorical variables have been proposed, along with structure learning algorithms. While existing optimization-based methods have limited scalability due to the large number of context-specific models, the constraint-based methods are more prone to error than even constraint-based DAG learning algorithms since more relations must be tested. We present a hybrid algorithm for learning context-specific models that scales to hundreds of variables while testing no more constraints than standard DAG learning algorithms. Scalable learning is achieved through a combination of an order-based MCMC algorithm and sparsity assumptions analogous to those typically invoked for DAG models. To implement the method, we solve a special case of an open problem recently posed by Alon and Balogh. The method is shown to perform well on synthetic data and real world examples, in terms of both accuracy and scalability.
Graphical posterior predictive classifier: Bayesian model averaging with particle Gibbs
Jun 06, 2018



In this study, we present a multi-class graphical Bayesian predictive classifier that incorporates the uncertainty in the model selection into the standard Bayesian formalism. For each class, the dependence structure underlying the observed features is represented by a set of decomposable Gaussian graphical models. Emphasis is then placed on the Bayesian model averaging which takes full account of the class-specific model uncertainty by averaging over the posterior graph model probabilities. An explicit evaluation of the model probabilities is well known to be infeasible. To address this issue, we consider the particle Gibbs strategy of Olsson et al. (2018b) for posterior sampling from decomposable graphical models which utilizes the Christmas tree algorithm of Olsson et al. (2018a) as proposal kernel. We also derive a strong hyper Markov law which we call the hyper normal Wishart law that allow to perform the resultant Bayesian calculations locally. The proposed predictive graphical classifier reveals superior performance compared to the ordinary Bayesian predictive rule that does not account for the model uncertainty, as well as to a number of out-of-the-box classifiers.