 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel image space formalism of Fourier domain interpolation neural networks for noise propagation analysis
Feb 27, 2024Purpose: To develop an image space formalism of multi-layer convolutional neural networks (CNNs) for Fourier domain interpolation in MRI reconstructions and analytically estimate noise propagation during CNN inference. Theory and Methods: Nonlinear activations in the Fourier domain (also known as k-space) using complex-valued Rectifier Linear Units are expressed as elementwise multiplication with activation masks. This operation is transformed into a convolution in the image space. After network training in k-space, this approach provides an algebraic expression for the derivative of the reconstructed image with respect to the aliased coil images, which serve as the input tensors to the network in the image space. This allows the variance in the network inference to be estimated analytically and to be used to describe noise characteristics. Monte-Carlo simulations and numerical approaches based on auto-differentiation were used for validation. The framework was tested on retrospectively undersampled invivo brain images. Results: Inferences conducted in the image domain are quasi-identical to inferences in the k-space, underlined by corresponding quantitative metrics. Noise variance maps obtained from the analytical expression correspond with those obtained via Monte-Carlo simulations, as well as via an auto-differentiation approach. The noise resilience is well characterized, as in the case of classical Parallel Imaging. Komolgorov-Smirnov tests demonstrate Gaussian distributions of voxel magnitudes in variance maps obtained via Monte-Carlo simulations. Conclusion: The quasi-equivalent image space formalism for neural networks for k-space interpolation enables fast and accurate description of the noise characteristics during CNN inference, analogous to geometry-factor maps in traditional parallel imaging methods.
Iterative RAKI with Complex-Valued Convolution for Improved Image Reconstruction with Limited Scan-Specific Training Samples
Jan 10, 2022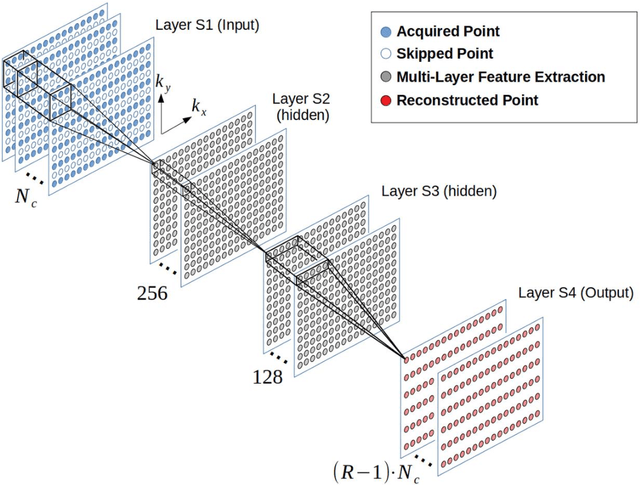
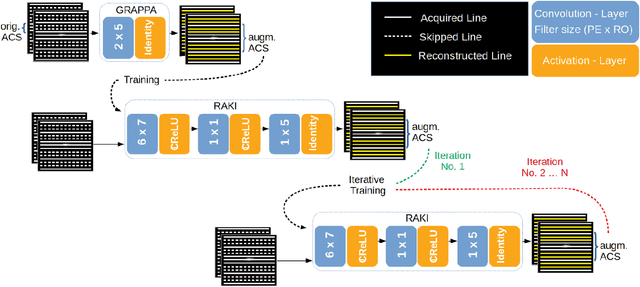

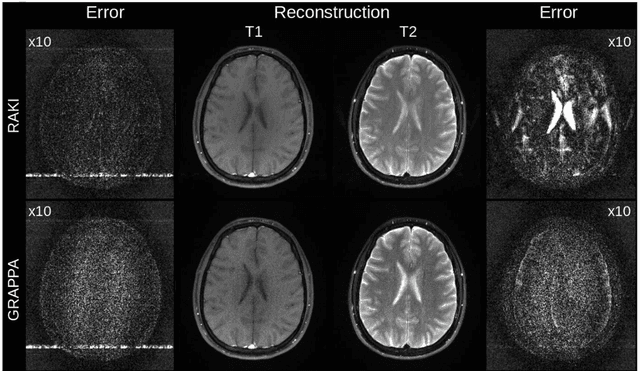
MRI scan time reduction is commonly achieved by Parallel Imaging methods, typically based on uniform undersampling of the inverse image space (a.k.a. k-space) and simultaneous signal reception with multiple receiver coils. The GRAPPA method interpolates missing k-space signals by linear combination of adjacent, acquired signals across all coils, and can be described by a convolution in k-space. Recently, a more generalized method called RAKI was introduced. RAKI is a deep-learning method that generalizes GRAPPA with additional convolution layers, on which a non-linear activation function is applied. This enables non-linear estimation of missing signals by convolutional neural networks. In analogy to GRAPPA, the convolution kernels in RAKI are trained using scan-specific training samples obtained from auto-calibration-signals (ACS). RAKI provides superior reconstruction quality compared to GRAPPA, however, often requires much more ACS due to its increased number of unknown parameters. In order to overcome this limitation, this study investigates the influence of training data on the reconstruction quality for standard 2D imaging, with particular focus on its amount and contrast information. Furthermore, an iterative k-space interpolation approach (iRAKI) is evaluated, which includes training data augmentation via an initial GRAPPA reconstruction, and refinement of convolution filters by iterative training. Using only 18, 20 and 25 ACS lines (8%), iRAKI outperforms RAKI by suppressing residual artefacts occurring at accelerations factors R=4 and R=5, and yields strong noise suppression in comparison to GRAPPA, underlined by quantitative quality metrics. Combination with a phase-constraint yields further improvement. Additionally, iRAKI shows better performance than GRAPPA and RAKI in case of pre-scan calibration and strongly varying contrast between training- and undersampled data.
Analytic Feature Selection for Support Vector Machines
Apr 20, 2013
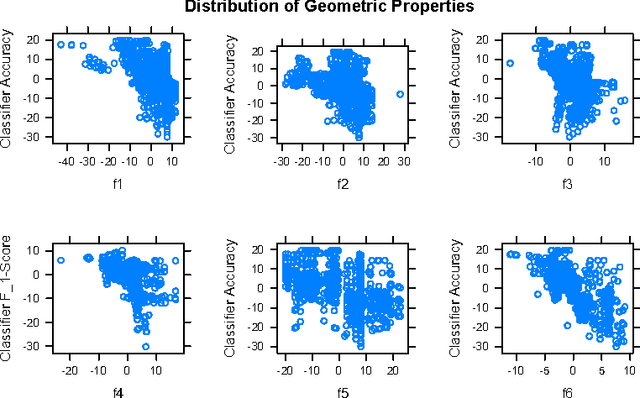

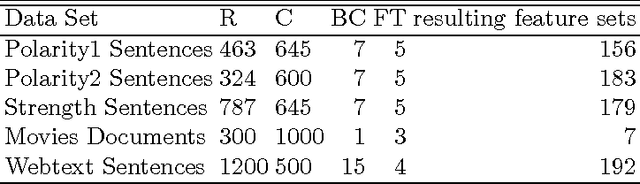
Support vector machines (SVMs) rely on the inherent geometry of a data set to classify training data. Because of this, we believe SVMs are an excellent candidate to guide the development of an analytic feature selection algorithm, as opposed to the more commonly used heuristic methods. We propose a filter-based feature selection algorithm based on the inherent geometry of a feature set. Through observation, we identified six geometric properties that differ between optimal and suboptimal feature sets, and have statistically significant correlations to classifier performance. Our algorithm is based on logistic and linear regression models using these six geometric properties as predictor variables. The proposed algorithm achieves excellent results on high dimensional text data sets, with features that can be organized into a handful of feature types; for example, unigrams, bigrams or semantic structural features. We believe this algorithm is a novel and effective approach to solving the feature selection problem for linear SVMs.