 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical learning by sparse deep neural networks
Nov 15, 2023We consider a deep neural network estimator based on empirical risk minimization with l_1-regularization. We derive a general bound for its excess risk in regression and classification (including multiclass), and prove that it is adaptively nearly-minimax (up to log-factors) simultaneously across the entire range of various function classes.
Classification by sparse additive models
Dec 04, 2022We consider (nonparametric) sparse additive models (SpAM) for classification. The design of a SpAM classifier is based on minimizing the logistic loss with a sparse group Lasso/Slope-type penalties on the coefficients of univariate components' expansions in orthonormal series (e.g., Fourier or wavelets). The resulting classifier is inherently adaptive to the unknown sparsity and smoothness. We show that it is nearly-minimax (up to log-factors) within the entire range of analytic, Sobolev and Besov classes, and illustrate its performance on the real-data example.
Generalization Error Bounds for Multiclass Sparse Linear Classifiers
Apr 13, 2022We consider high-dimensional multiclass classification by sparse multinomial logistic regression. Unlike binary classification, in the multiclass setup one can think about an entire spectrum of possible notions of sparsity associated with different structural assumptions on the regression coefficients matrix. We propose a computationally feasible feature selection procedure based on penalized maximum likelihood with convex penalties capturing a specific type of sparsity at hand. In particular, we consider global sparsity, double row-wise sparsity, and low-rank sparsity, and show that with the properly chosen tuning parameters the derived plug-in classifiers attain the minimax generalization error bounds (in terms of misclassification excess risk) within the corresponding classes of multiclass sparse linear classifiers. The developed approach is general and can be adapted to other types of sparsity as well.
Multiclass classification by sparse multinomial logistic regression
Mar 26, 2020In this paper we consider high-dimensional multiclass classification by sparse multinomial logistic regression. We propose a feature selection procedure based on penalized maximum likelihood with a complexity penalty on the model size and derive the nonasymptotic bounds for misclassification excess risk of the resulting classifier. We establish also their tightness by deriving the corresponding minimax lower bounds. In particular, we show that there exist two regimes corresponding to small and large number of classes. The bounds can be reduced under the additional low noise condition. Implementation of any complexity penalty based procedure, however, requires a combinatorial search over all possible models. To find a feature selection procedure computationally feasible for high-dimensional data, we propose multinomial logistic group Lasso and Slope classifiers and show that they also achieve the optimal order in the minimax sense.
High-dimensional classification by sparse logistic regression
Mar 08, 2018We consider high-dimensional binary classification by sparse logistic regression. We propose a model/feature selection procedure based on penalized maximum likelihood with a complexity penalty on the model size and derive the non-asymptotic bounds for the resulting misclassification excess risk. The bounds can be reduced under the additional low-noise condition. The proposed complexity penalty is remarkably related to the VC-dimension of a set of sparse linear classifiers. Implementation of any complexity penalty-based criterion, however, requires a combinatorial search over all possible models. To find a model selection procedure computationally feasible for high-dimensional data, we extend the Slope estimator for logistic regression and show that under an additional weighted restricted eigenvalue condition it is rate-optimal in the minimax sense.
Classification with many classes: challenges and pluses
Nov 12, 2017
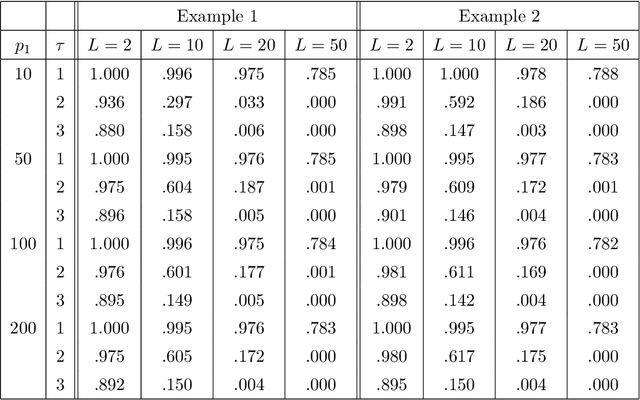


The objective of the paper is to study accuracy of multi-class classification in high-dimensional setting, where the number of classes is also large ("large $L$, large $p$, small $n$" model). While this problem arises in many practical applications and many techniques have been recently developed for its solution, to the best of our knowledge nobody provided a rigorous theoretical analysis of this important setup. The purpose of the present paper is to fill in this gap. We consider one of the most common settings, classification of high-dimensional normal vectors where, unlike standard assumptions, the number of classes could be large. We derive non-asymptotic conditions on effects of significant features, and the low and the upper bounds for distances between classes required for successful feature selection and classification with a given accuracy. Furthermore, we study an asymptotic setup where the number of classes is growing with the dimension of feature space and while the number of samples per class is possibly limited. We discover an interesting and, at first glance, somewhat counter-intuitive phenomenon that a large number of classes may be a "blessing" rather than a "curse" since, in certain settings, the precision of classification can improve as the number of classes grows. This is due to more accurate feature selection since even weaker significant features, which are not sufficiently strong to be manifested in a coarse classification, can nevertheless have a strong impact when the number of classes is large. We supplement our theoretical investigation by a simulation study and a real data example where we again observe the above phenomenon.