 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification with many classes: challenges and pluses
Paper and Code
Nov 12, 2017
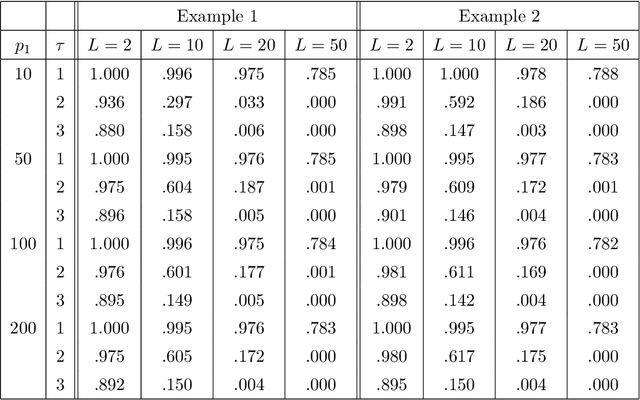


The objective of the paper is to study accuracy of multi-class classification in high-dimensional setting, where the number of classes is also large ("large $L$, large $p$, small $n$" model). While this problem arises in many practical applications and many techniques have been recently developed for its solution, to the best of our knowledge nobody provided a rigorous theoretical analysis of this important setup. The purpose of the present paper is to fill in this gap. We consider one of the most common settings, classification of high-dimensional normal vectors where, unlike standard assumptions, the number of classes could be large. We derive non-asymptotic conditions on effects of significant features, and the low and the upper bounds for distances between classes required for successful feature selection and classification with a given accuracy. Furthermore, we study an asymptotic setup where the number of classes is growing with the dimension of feature space and while the number of samples per class is possibly limited. We discover an interesting and, at first glance, somewhat counter-intuitive phenomenon that a large number of classes may be a "blessing" rather than a "curse" since, in certain settings, the precision of classification can improve as the number of classes grows. This is due to more accurate feature selection since even weaker significant features, which are not sufficiently strong to be manifested in a coarse classification, can nevertheless have a strong impact when the number of classes is large. We supplement our theoretical investigation by a simulation study and a real data example where we again observe the above phenomenon.