 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for Fine-grained Classification Using Semi-supervised Learning and Visual Transformers
May 17, 2023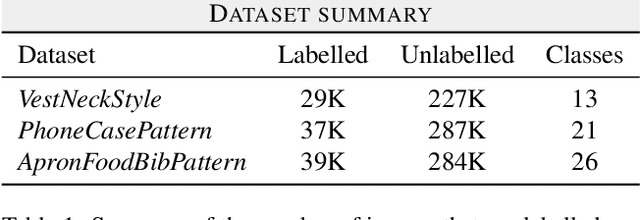

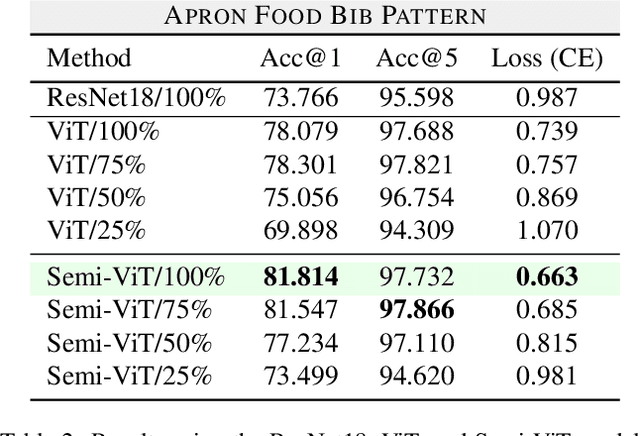
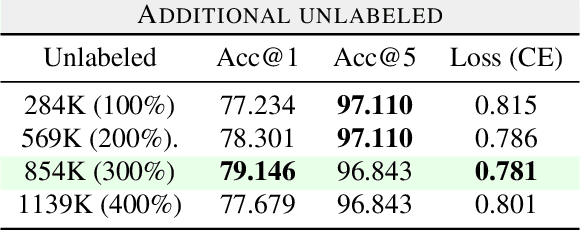
Fine-grained classification is a challenging task that involves identifying subtle differences between objects within the same category. This task is particularly challenging in scenarios where data is scarce. Visual transformers (ViT) have recently emerged as a powerful tool for image classification, due to their ability to learn highly expressive representations of visual data using self-attention mechanisms. In this work, we explore Semi-ViT, a ViT model fine tuned using semi-supervised learning techniques, suitable for situations where we have lack of annotated data. This is particularly common in e-commerce, where images are readily available but labels are noisy, nonexistent, or expensive to obtain. Our results demonstrate that Semi-ViT outperforms traditional convolutional neural networks (CNN) and ViTs, even when fine-tuned with limited annotated data. These findings indicate that Semi-ViTs hold significant promise for applications that require precise and fine-grained classification of visual data.